
Kaggle回归问题Mercedes——Benz Greener Manufacturing
这是我在大三选修课的课程设计,内容参考了Kaggle上高赞的代码,有详细批注,整体比较基础,结构相对完整,便于初学者学习。这个是一个回归问题,我的另外一篇博客《Kaggle分类问题Titanic——Machine Learning from Disaster》介绍了回归问题。除此之外我的《电商评论文本挖掘》也是我当年的课程设计,也有详细的批注,相比这个难度会稍微高些。题目背景:自1886年第一辆奔
前言
这是我在大三选修课的课程设计,内容参考了Kaggle上高赞的代码,有详细批注,整体比较基础,结构相对完整,便于初学者学习。这个是一个回归问题,我的另外一篇博客《Kaggle分类问题Titanic——Machine Learning from Disaster》介绍了回归问题。除此之外我的《电商评论文本挖掘》也是我当年的课程设计,也有详细的批注,相比这个难度会稍微高些。
1 题目介绍
题目背景:自1886年第一辆奔驰汽车问世以来,梅赛德斯奔驰一直代表着重要的汽车创新。为确保每一款独特的汽车配置在上路之前的安全性和可靠性,Daimler的工程师开发了一个强大的测试系统。但是,如果没有强大的算法,为如此多可能的特征组合计算他们的测试系统的速度,这将是复杂且耗时的。而我们的任务是使用代表奔驰汽车功能的不同排列的数据集,以预测通过测试所需的时间。这个时间将有助于更快的测试,在不降低Daimler标准的情况下,减少二氧化碳排放。
数据介绍:数据匿名,没有具体介绍,共有378个变量,分别为时间y以及其他相关特征。

2 数据清洗
1)对数据进行概览。

2)查看所有变量的种类。


3)查看为object类的列

4)查看是否有缺失值(无)
5)查看int列,可以看出大部分整数列的值都是0与1,有些全为0的可以将他们删去。


3 数据可视化分析
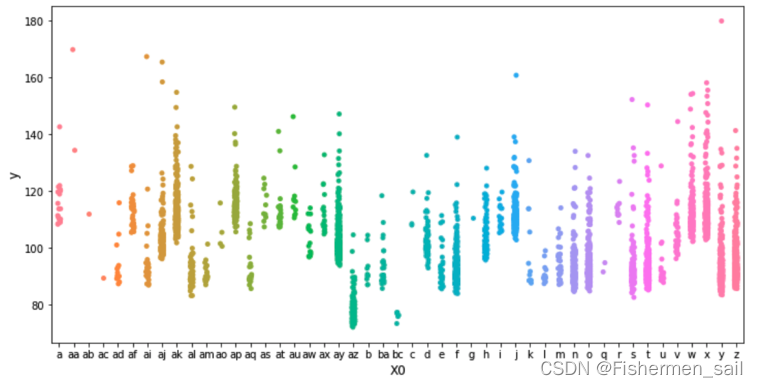
1)利用stripplot绘制X0与y的关系。

2)利用boxplot绘制X2与y的关系。

3)利用violinplot绘制X3与y的关系。

4)利用barh绘制水平条形图,展现01变量0与1的比重。

5)利用heatmap查看每列0或1所对应的平均y值,可以发现出现了很好的区分。

6)利用regplot绘制ID列的线性回归图,可以看出随着id的增大,有个轻微下降的趋势。

7)利用violinplot查看查看训练集与测试集ID的分布,可以看出ID是随机的。

8)根据xgboost,得到重要的变量。


9)根据随机森林得到重要的变量。


4 模型训练
使用PCA、ICA、tSVD等对数据进行降维。


使用TPOT自动选择机器学习模型和参数。搜索整个管道空间是特别耗时的,在默认的TPOT参数下(100 generations with 100 population size),TPOT将在完成前评估1万个管道配置。网格搜索1万个超参数组合用于机器学习算法,而且用10倍的交叉验证来评估这1万个模型,这意味着大约有10万个模型在一个网格搜索的训练数据中被匹配和评估。这是一个非常耗时的过程,即使对于像决策树这样的简单模型也是如此。
典型的TPOT运行将需要数小时到数天才能完成(除非是一个小数据集),但是可以中断运行,并看到目前为止最好的结果。TPOT还提供warm_start参数,可以从中断的地方重新启动之前运行的TPOT。
generations(default=100),运行管道优化过程的迭代次数。一定是正数。一般来说,值越大,性能越好。
population_size(default=100),在每一代遗传中保留的个体数(基因编程)。一定是正数。一般来说,值越大,性能越好。
verbosity(default=0),0将不会打印任何东西;1将打印很少的信息;2打印更多的信息并提供一个进度条;3打印所有内容,并提供一个进度条。

导出TPOT选择好的模型与其参数。

5 源码
为了更好的观看效果,我将源码放在了Github上,如有帮助,希望点个星星支持一下,感谢。

鸿蒙生态一站式服务平台。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)