
YOLO-V5 算法和代码解析系列(二)—— 【train.py】核心内容
文章目录:调试设置,整体结构,代码解析,Model,Trainloader,分布式训练,Freeze,Optimizer,Scheduler,EMA
调试设置
-
调试平台:Ubuntu,VSCode
-
工程首次设置调试模式时,软件界面没有调试文件【launch.json】,需要按照下面的流程创建

-
创建完成后,就会生成下图中的【launch.json】文件,后续只需打开编辑即可,

-
打开【launch.json】的操作流程如下图所示,

首次打开,默认内容如下,

-
配置调试文件
根据个人需求配置参数,主要是修改程序名称【
"program"】,添加运行参数【"args"】,具体如下面的代码片段所示,{ // 使用 IntelliSense 了解相关属性。 // 悬停以查看现有属性的描述。 // 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ // train.py { "name": "Python: Current File", "type": "python", "request": "launch", "program": "train.py", "console": "integratedTerminal", "justMyCode": true, "args":["--data", "coco128.yaml", "--cfg", "", "--weights", "yolov5s.pt", "--batch-size", "1", "--device", "1", "--epoch", "10", "--workers", "1"] } ] }
整体结构
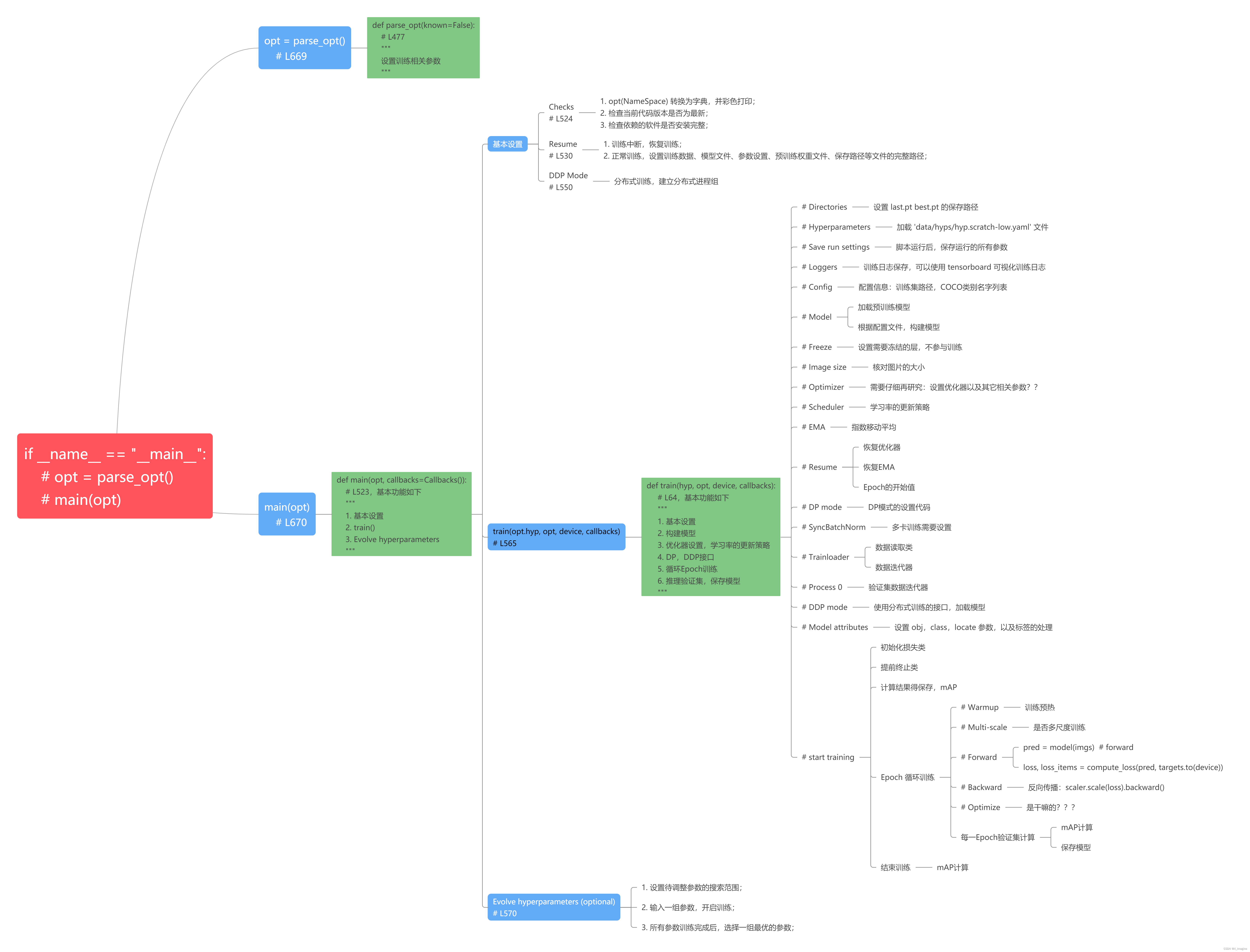
该篇博文主要目的不是帮助读者深入理解每一个知识点,每一行代码。【主要目的】:从整体上弄清楚【yolov5】整体的运行逻辑和结构,一个完整的深度学习项目,应该包含哪些模块,哪些设置。下面的思维导图,大概展示了【train.py】相关的所有知识点,以及整体的运行结构。

代码解析
作者为了代码的健壮性,稳定性,【train.py】内容非常多,可能会感觉有一些繁杂。初次阅读代码可能会抓不住重点,进而在一些不重要的功能模块浪费时间。下面的内容,不会解析所有代码,而是解析【核心模块】和【核心代码】。
-
函数入口如下,parse_opt():配置参数;main():核心功能函数
if __name__ == "__main__": # 参数配置 opt = parse_opt() # 核心功能函数:基本设置,train(),动态调参 main(opt) -
参数配置
基本功能:解析命令行参数,包括训练参数,学习率,模型文件,数据路径,测试参数等;
基本使用:库 【argparse】的使用,(1)导入库【
argparse】;
(2)创建解析对象【parser】;
(3)添加命令行参数,以及默认的参数和选项【add_argument()】;
(4)解析添加的参数【parser.parse_args()】;流程非常简单,示例如下,
import argparse parser = argparse.ArgumentParser() parser.add_argument('--weights', type=str, default=ROOT /'yolov5s.pt', help='initial weights path') opt = parser.parse_known_args()[0] if known else parser.parse_args() -
解析【
main()】 函数
如【整体结构】中的思维导图所示,【main()】主要包括三大部分:基本设置,训练核心函数(train),动态调参。下面逐步解析每一个部分的核心内容:
基本设置:Resume为了调试 Resume,需要添加【debug】参数:【“–resume”, “runs/train/exp/weights/best.pt”】,表示从该路径下的【best.pt】恢复训练。具体解释,见代码注释,
# Resume # if的判断条件: # opt.resume:true; # check_wandb_resume(opt):false,通常不会用wandb工具; # opt.evolve:动态调参的参数,通常为false; if opt.resume and not check_wandb_resume(opt) and not opt.evolve: # resume an interrupted run # 判断【opt.resume】是否为字符串,true # ckpt: 'runs/train/exp/weights/best.pt' ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent path # 检查【ckpt】文件是否存在 assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist' # 重新加载中断训练前保存的配置文件信息,保存名字为【opt.yaml】 with open(Path(ckpt).parent.parent / 'opt.yaml', errors='ignore') as f: opt = argparse.Namespace(**yaml.safe_load(f)) # replace # 恢复训练,重新更新模型参数 opt.cfg, opt.weights, opt.resume = '', ckpt, True # reinstate # 打印日志:Resuming training from runs/train/exp/weights/best.pt LOGGER.info(f'Resuming training from {ckpt}') else: # 返回参数的具体路径 # opt.data: 'coco128.yaml' ---> '/home/slam/kxh-1/2DDection/yolov5/data/coco128.yaml' # opt.hyp: PosixPath('data/hyps/hyp.scratch-low.yaml') ---> 'data/hyps/hyp.scratch-low.yaml' # opt.weights: 'yolov5s.pt' ---> 'yolov5s.pt' # opt.project: PosixPath('runs/train') ---> 'runs/train' opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \ check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks # cfg:模型的结构配置文件,weights:pt文件。两者必须提供一个,才能构建出网络结构 assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified' if opt.evolve: if opt.project == str(ROOT / 'runs/train'): # if default project name, rename to runs/evolve opt.project = str(ROOT / 'runs/evolve') opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume if opt.name == 'cfg': opt.name = Path(opt.cfg).stem # use model.yaml as name # 建立模型保存路径 opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))基本设置:DDP Mode
DDP 是官方推荐的并行训练模式,下面的代码片段仅仅是设置【多进程组】。该篇文章并不解释DDP的训练模式,后续博文文章会专门解释DDP,此处不作深入解析。
# DDP mode # 设置设备ID,以及检查设备的显卡,cuda信息,具体输出如下: # YOLOv5 🚀 v6.1-263-g0537e8dd Python-3.7.13 torch-1.10.0 CUDA:1 (NVIDIA GeForce RTX 2080 Ti, 11019MiB) device = select_device(opt.device, batch_size=opt.batch_size) if LOCAL_RANK != -1: msg = 'is not compatible with YOLOv5 Multi-GPU DDP training' assert not opt.image_weights, f'--image-weights {msg}' assert not opt.evolve, f'--evolve {msg}' assert opt.batch_size != -1, f'AutoBatch with --batch-size -1 {msg}, please pass a valid --batch-size' assert opt.batch_size % WORLD_SIZE == 0, f'--batch-size {opt.batch_size} must be multip of WORLD_SIZE' assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command' torch.cuda.set_device(LOCAL_RANK) device = torch.device('cuda', LOCAL_RANK) # DDP Mode:首先初始化多进程组 dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo") -
解析【
train】函数
训练的核心模块,包含很多内容(参考上述的整体结构图)。下面主要介绍核心的模块,具体如下Model
这一部分包含模型的构建和初始化,后续博文会详细讲解,这里不作陈述。
Trainloader
这一部分主要是设置数据读取迭代器,数据读取类,数据增强等,后续博文会详细讲解,这里不作陈述。
分布式训练
这一部分主要是设置DP,DDP分布式训练,后续博文会详细讲解,这里不作陈述。
Freeze
下面的代码片段,简单展示了冻结层的基本设置。简单说,就是将该层的权重更新关闭,也就冻结了当前层的权重更新。
冻结层操作通常用于迁移学习,具体可以参考 https://github.com/ultralytics/yolov5/issues/1314.
# Freeze # 设置要冻结的层的ID freeze = [f'model.{x}.' for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # layers to freeze # 遍历 model 的参数,k:层的名字,v: 权重值 # k: 'model.0.conv.weight' # v.shape: torch.Size([32, 3, 6, 6]) for k, v in model.named_parameters(): # 设置是否需要计算梯度的标记,True:优化该层,False:冻结该层 v.requires_grad = True # train all layers if any(x in k for x in freeze): LOGGER.info(f'freezing {k}') v.requires_grad = FalseOptimizer
下面的代码主要是设置损失累积,根据实际需要调整,
# Optimizer # 预先设定的【batch-size】 nbs = 64 # nominal batch size # 累计【accumulate】次损失后,在进行反向传播优化,变向的是在增大batch-size? accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing # 实际 batch_size <= nbs,权重衰减值不变,需要累积损失; # 实际 batch_size > nbs, 权重值乘以大于1的系数,不需要累积损失; hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}")优化器参数组:借助参数组,满足不同的优化需求,代码如下,
# 初始化参数组的保存列表 g = [], [], [] # optimizer parameter groups # 列举出【nn】模块中的名字和值(比如,('Conv2d', <class 'torch.nn.modules.conv.Conv2d'>), # 然后,把带有【Norm】字段的名字【k】对应的值【v】的添加到【bn】 bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d() # 将当前模型中的【weights】,【bias】,【bn_weight】分开,并分别存入空列表【g】中 # 存储结果:len(g)=3,len(g[0])=60,len(g[1])=57,len(g[2])=60 for v in model.modules(): if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias g[2].append(v.bias) if isinstance(v, bn): # weight (no decay) g[1].append(v.weight) elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay) g[0].append(v.weight)选择优化器:选择是【SGD】,默认传入待优化参数为【g[2],bias】,然后再添加其它待优化的参数,
# 提供三种优化器, 传入不同的参数 if opt.optimizer == 'Adam': optimizer = Adam(g[2], lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum elif opt.optimizer == 'AdamW': optimizer = AdamW(g[2], lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum else: optimizer = SGD(g[2], lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True) # 更新优化器的待优化参数 # 显然还要添加核心的优化参数,【weights,并且指定了单独的权重衰减值】,【bn】和【bias】无法使用权重衰减系数 optimizer.add_param_group({'params': g[0], 'weight_decay': hyp['weight_decay']}) # add g0 with weight_decay optimizer.add_param_group({'params': g[1]}) # add g1 (BatchNorm2d weights) LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__} with parameter groups " f"{len(g[1])} weight (no decay), {len(g[0])} weight, {len(g[2])} bias") del g关于建立优化器组(optimizer group)的简明解释:
模型的参数可以被分成不同的组,然后赋予单独的优化参数,具体例子如下
optim.SGD([ {'params': model.base.parameters()}, {'params': model.classifier.parameters(), 'lr': 1e-3} ], lr=1e-2, momentum=0.9)上述代码片段表示:【model.base】的参数使用默认的学习率【1e-2】,【model.classifier】的参数使用学习率【1e-3】,所有的参数动使用的动量为【0.9】
Scheduler
学习率调整策略,
# Scheduler if opt.cos_lr: # 余弦调整策略,自定义调整规则,然后传入Pytorch API接口 lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf'] else: # 线性调整,传入参数x lf = lambda x: (1 - x / epochs) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)绘制两种学习率的曲线图,官方已提供该函数:
from utils.plots import plot_lr_scheduler plot_lr_scheduler(optimizer, scheduler, epochs)绘制结果如下,左图是余弦调整方式,右图是线性调整方式,


EMA
Tensorflow框架 —— tf.ExponentalMovingAverage(),解析了EMA的理论部分,可以大概了解一下具体原理。 下面是【yolo-v5】实现的指数移动平均(EMA)的代码,具体解析见注释如下,
EMA的操作对象:网络训练中,模型的优化变量,比如weights,bias.
EMA的操作方式:对一定步骤内的历史变量进行指数移动平均,也就是对历史变量计算平均值。
EMA的作用:保证模型测试的稳定性,不至于由于异常值,导致推理结果波动太大。class ModelEMA: """ Updated Exponential Moving Average (EMA) from https://github.com/rwightman/pytorch-image-models Keeps a moving average of everything in the model state_dict (parameters and buffers) For EMA details see https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage """ def __init__(self, model, decay=0.9999, tau=2000, updates=0): # Create EMA # 构建EMA,.eval()固定BN的参数,不参与平均 self.ema = deepcopy(de_parallel(model)).eval() # FP32 EMA # if next(model.parameters()).device.type != 'cpu': # self.ema.half() # FP16 EMA self.updates = updates # number of EMA updates # 每一次更新的decay值 self.decay = lambda x: decay * (1 - math.exp(-x / tau)) # decay exponential ramp (to help early epochs) # 将参数全部置为False,不进行梯度计算 for p in self.ema.parameters(): p.requires_grad_(False) def update(self, model): # Update EMA parameters with torch.no_grad(): # 暂时停止自动求导模块运算 self.updates += 1 d = self.decay(self.updates) # 更新新的decay值 # 获取模型的所有参数,包括训练参数和非训练参数 msd = de_parallel(model).state_dict() # model state_dict # 计算新的参数,并更新对应的影子参数(存储在ema,默认为False) for k, v in self.ema.state_dict().items(): if v.dtype.is_floating_point: v *= d v += (1 - d) * msd[k].detach() def update_attr(self, model, include=(), exclude=('process_group', 'reducer')): # Update EMA attributes copy_attr(self.ema, model, include, exclude)YOLO-V5中使用流程,
初始化【EMA】对象
# EMA ema = ModelEMA(model) if RANK in {-1, 0} else None更新参数
ema.update(model) -
动态调参
实际未用,暂不解析,后续若用,会更新博文。

鸿蒙生态一站式服务平台。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)