
关于冗余和容错的一些总结(Redundancy and fault tolerance)
在项目中一直提到冗余和容错,为了深入理解这个概念,查了一些资料总结一下。
冗余和容错(Redundancy and fault tolerance)
在项目中一直提到冗余和容错,为了深入理解这个概念,查了一些资料总结一下。
概述
冗余和容错这两个概念与系统的可靠性(Reliability)密不可分。冗余是容错的核心。这里以VLSI为背景进行理解。
容错(fault tolerance):就是容许错误(fault tolerance),是指设备的一个或多个关键部分发生故障时,能够自动地进行检测与诊断,并采取相应措施,保证设备维持其规定功能,或牺牲性能来保证设备在可接受范围内继续工作。
冗余(Redundancy):多余资源,冗余的技术可供用来处理故障。
提高系统的可靠性一般有两种办法:
- 采用缜密的设计和质量控制方法来尽量减少故障出现的概率。
- 以冗余资源为代价来换取可靠性。
利用前一种方法来提高系统的可靠性是有限的,无论设计多么稳健(robust),100%无故障设计都是不可能的。要想进一步的提高必须采用容错技术:正视生活中故障存在的事实,并结合技术来容忍(tolerance)这些故障,同时仍然提供可接受的服务水平。
背景和应用
容错控制技术在国外发展较早,最先冯·诺依曼提出。他在1952 年作了一系列关于用重复逻辑模块改善系统可靠性的报告;1956 年,他发表了论文《概率逻辑及用不可靠元件设计可靠的结构》。随着八十年代微型计算机的迅速发展和广泛应用,容错技术也得到飞速发展,常见的应用领域有:
- 关键应用:飞机、核反应堆、医疗设备
- 恶劣环境:容易受到高振动、温度、湿度、电磁干扰、颗粒撞击的系统
- 高计算系统:由数百万台设备组成的复杂系统
电子系统中发生的错误可以是暂时的,也可以是永久性的。
-
**瞬时故障 (Transient Faults)– 相对较短的时间后消失。例如,由于某些电磁干扰而虚假更改内容内容的存储单元。用正确的内容覆盖存储单元将使故障消失。
-
永久性故障 (Permanent Faults)– 永不消失,必须维修或更换组件。
举个例子:设备某一部分的故障和错误(fault and error)可能会传播到整个系统。例如,内存模块数据输出端的“0”卡住(永久接地)可能会向处理器提供错误的逻辑“0”数据(而逻辑“1”是正确的数据)。这种错误的数据值将由处理器处理,最终可能会生成错误的结果。在这种情况下,处理器单元没有故障,但是由于内存模块中的故障,结果中的错误发生了传播(propagate)。
容错中的冗余(Redundancy in Fault Tolerance)
VLSI 系统大致可以被视为以下 3 层的集合:
- 硬件层(处理内核、存储器等)
- 软件层(操作系统、程序说明)
- 互连层(基于总线或片上网络)
设计人员在这些系统层中引入了几种技术来处理瞬时错误和永久性错误,这些技术在某些方面结合了冗余的概念。因此可以说*“冗余是容错的核心”。*以下是在容错中处理的四种不同形式的冗余:
硬件冗余 (Hardware Redundancy,HR)
这种情况下向系统引入了完整模块或子模块的多个冗余单元。冗余单元与实际单元一起执行相同的工作以检测故障并屏蔽它。三重模块化冗余 (Triple Modular Redundancy,TMR) 是硬件冗余的一种非常常见的实现。假设模块是一个处理器。在 TMR 系统中,另外 2 个相同的处理器将在那里执行相同的指令集以及主指令集。所有处理器的输出汇集到一个投票单元(Voter unit),它将比较所有处理器的输出,并对正确结果进行多数表决,如果有错误结果,则丢弃错误结果。
Voter unit应该类似于SV测试平台中的checker。
软件冗余 (Software Redundancy,SR)
这种情况下是由开发同一程序(软件)的不同版本(different versions of the same program (software))的多个程序员团队处理的。这与同一个程序的不同版本会在同一个输入集上产生相同的错误是不同的。
-
当软件的多个版本同时在多个相同的模块上运行时,SR 使用 硬件冗余HR;
-
当多个版本在相同的硬件模块上一个接一个地运行时,SR 使用 时间冗余TR。
信息冗余 (Information Redundancy,IR)
这种情况下应该以**“奇偶校验”(parity)**一词开头,这会使我们熟悉的印象。信息冗余将一些冗余位添加到原始数据位以检测错误,甚至有时纠正原始信息中的错误。这些附加位称为校验位。汉明码、循环码、校验和等是信息冗余的不同形式。
时间冗余 (Time Redundancy,TR)
在VLSI系统中遇到的大多数故障/错误都是瞬态( transient)的,在很小的时间间隔后就会消失。因此,如果故障是暂时性的,则重新执行( re-execution)在某个时间之前产生错误的部分代码很大可能不会再次产生错误。这种技术需要花费额外的时间来获得正确的结果,因此称为时间冗余。
根据需求,以及考虑VLSI的面积、功率和性能,综合考虑冗余的实施方式。
| 冗余 | 面积 Penalty | 性能 Penalty | 功耗 Penalty |
|---|---|---|---|
| 高 | 低 | 适中 | 关键系统:航空电子设备、汽车 |
| 当有时间冗余时高 | 当有时间冗余时高 | 适中 | 复杂计算系统 |
| 低 | 高 | 低 | 计算和互联 |
| Sometimes High like RAID | 高 | 低 | 通信和存储 |
缺陷、错误和故障(Defects, Errors, and Faults)
本节主要意会英文词汇,不确定专业名词的翻译是否准确。
在电子工业中产品中的不正确( incorrectness )以多种方式描述,这可能会在理解术语**缺陷,错误和故障(Defects, Errors, and Faults)**时造成混淆。虽然这些术语在VLSI测试领域可以互换,但这里我们给出精确的定义。
缺陷(Defects):电子系统中的缺陷是实现的硬件与其预期设计之间的意外差异。 缺陷可以是工艺缺陷、材料缺陷、老化缺陷和包装缺陷。
错误(Errors):有缺陷(defective)的系统产生的错误输出信号称为错误(Errors)。 错误(Errors)是某种“缺陷(Defects)”造成的结果。
故障(Faults):抽象功能层面(abstracted function level)上对缺陷(Defects)的表示称为故障(Faults)。 错误(Errors或者failure)可以是硬件缺陷(Defects)或软件/编程错误(mistake或者bug)。
理解区别
电子系统中的故障(Faults)是可以转化为故障(Faults)的缺陷(Defects)。 一个非常小的缺陷(Defects),例如冻结的内存位、卡住故障、软件中未初始化的变量、α粒子撞击或宇宙射线电离都可以被视为故障(Faults)。
A very small defect, such as a frozen memory bit, a stuck-at fault, an uninitialized variable in software, an alpha particle hit or cosmic ray ionization can be considered as a fault.
错误(Errors)可以被视为可能导致系统内出现意外行为的下一级故障(Faults)。 诸如状态变量的错误值、进入无限循环或计算结果不正确之类的东西可能被视为系统错误(Errors)。 通常,数据从正确值变为其他值的损坏称为错误(Errors)。 Failure可能被视为下一级的错误(Errors),这会引发系统某些部分无法按预期运行的情况 。
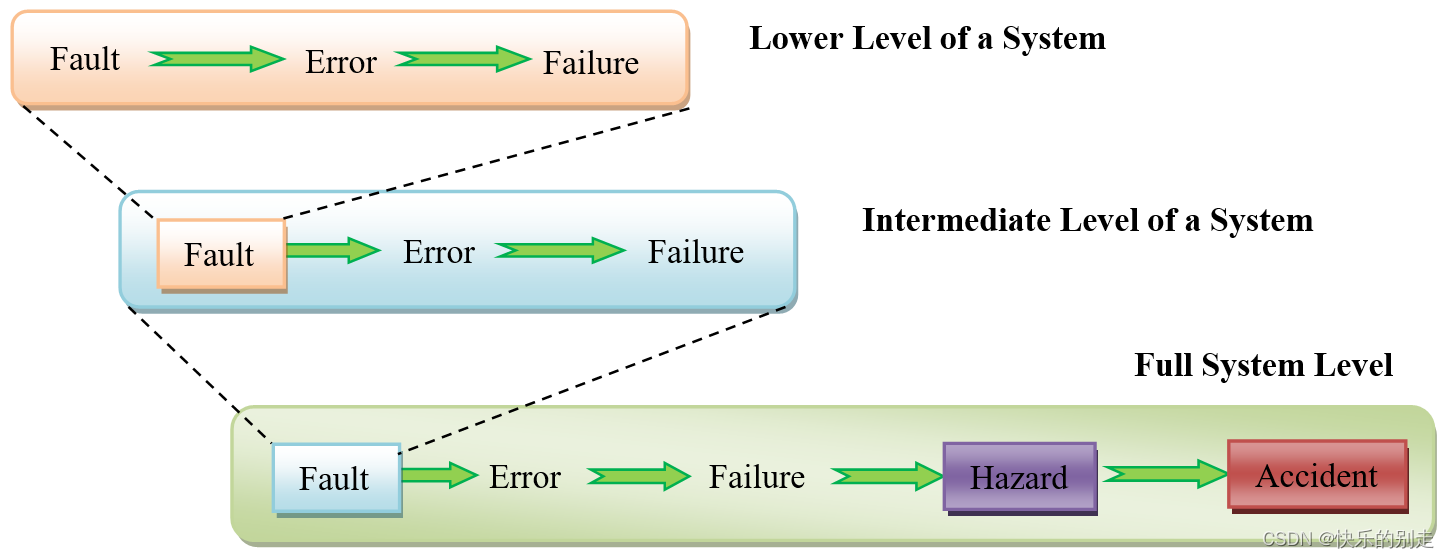
故障(Faults)可以是暂时的 (Transient Faults),也可以是永久的(Permanent Faults)。
例如,α粒子撞击或宇宙射线电离可能会改变存储在存储位单元中的值,该值可以通过重写正确的值来纠正。这种类型的内存错误可以被视为暂时性故障 (Transient Faults)。
然而,由于巨大的功耗,产生的大量热量可能会烧毁电路。由于电路永久损坏无法进一步工作,因此被视为永久性故障(Permanent Faults)。
一些例子
例 1 **(硬件缺陷)**考虑一个AND门,其两个输入连接到“a”,“b”,输出连接到“c”。假设连接到“b”的输入连接错误并且接地。该系统的功能输出,如实现的那样,是c = 0,而不是正确的输出c = ab。对于这个系统,我们有:

缺陷(Defects):接地短路。
故障(Faults):信号 b 卡在逻辑 0。
错误(Errors): a = 1,b = 1,输出 c = 0;正确的输出 c = 1 。请注意,该错误不是永久性的。只要至少有一个输入为 0,输出中就没有错误。
例2(硬件缺陷)
考虑一个加法器电路,输出线固定在 1; 它始终保持值 1,与输入操作数的值无关。这是一个故障(Faults),但还不是错误(Errors)。
当使用加法器并且该行上的结果应该是 0 而不是 1 时,这个故障(Fault)会导致错误(Error)。
例3(软件/编程错误)
考虑一个子程序(subroutine),它的功能是计算sin(x),但由于编程错误而计算sin(x)的绝对值。仅当使用该特定子例程并且正确结果为负数时,这个mistake才会导致执行错误(Error)。
故障(Fault)和错误(Error)都可以在整个系统中传播。例如,如果芯片将电源短路到地,则可能导致附近的芯片发生故障。错误可能会传播,因为一个单元的输出被其他单元用作输入。
容错中的可靠性和可用性(Reliability and Availability in Fault Tolerance)
可靠性(Reliability),R(t):系统在整个时间间隔[0,t]内连续运行的概率,假设它在时间0时运行。该度量适用于即使是短暂中断也会产生高昂代价的应用场合。一个例子是控制车辆自动制动的计算机,如果故障会导致事故。因此,在维修条件不可用的情况下计算可靠性。
可用性(Availability),A(t):系统在整个时间间隔[0,t]内处于上升状态。该度量适用于连续性能不重要但系统长时间停机产生高昂代价的应用场合。淘宝京东需要高可用性。这是因为停机可能会拖延客户并导致销售损失;然而,偶尔的暂时故障是可以很好地容忍的(比如某年春晚清空购物车的时候)。
例如,一个网站(淘宝)每小时都会发布一个带有奖品的测验(整点秒杀清空购物车)。由于访问人数众多,服务器每小时停机一分钟。但过了一分钟,随着流量下降,网站再次上升。这种系统的**平均故障间隔时间(Mean Time Between Failure ,MTBF)**仅为1小时,因此可靠性(Reliability)较低;然而,它的可用性(Availability)很高。
可用性计算按如下方式进行。网站每小时启动 59 分钟,关闭 1 分钟。
可用性 Availability = 59/60 = 0.983
由于该系统在98.3%的时间内可用,因此我们可以将其视为高可用性(highly-available)的系统。

-
**平均故障时间(**Mean Time To Failure, MTTF):系统在停机之前保持正常运行(直到发生故障)并且必须进行维修或更换的平均时间。
-
**平均故障间隔时间(Mean Time Between Failures, MTBF):**两次连续失败之间的平均时间。
-
**平均修复时间(Mean Time to Repair, MTTR)**上述两者之间的差异是由于第一次故障后修复系统所需的时间。
参考文献:
Redundancy and fault tolerance (article) | Khan Academy 可汗学院简述互联网中的redundancy and fault tolerance
一文读懂“容错”与“冗余”技术-面包板社区 (eet-china.com)
Need of Fault Tolerant VLSI System Design - VLSIFacts
Redundancy in Fault Tolerance - VLSIFacts

鸿蒙生态一站式服务平台。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)