
Ceph分布式存储自动化运维平台开发实践
这个逻辑架构设计强调了后端与前端的协同工作,通过异步任务处理提高了系统的实时性和处理能力。前端使用了Vue3和Arco Design构建直观美观的用户界面,而后端则通过Tornado提供高性能的Web服务。 Celery的引入使得系统能够更好地应对复杂的任务和高并发情况。整体上,这个设计能够应对Ceph集群自动化运维的各种需求。
1. 背景介绍
1.1 什么是Ceph?
Ceph是一个开源的分布式存储系统,其核心理念在于提供高可靠性和高可扩展性的存储解决方案。这一理念基于RADOS系统的设计和实现,使Ceph能够应对大规模的存储需求,并在硬件故障、负载增加等各种情况下保持稳定性。其基于强大的RADOS(可靠、自适应、分布式对象存储)系统构建,支持对象存储、块存储和文件存储。Ceph以其强大的容错性、高性能和灵活性而闻名,适用于各种规模的存储需求。
1.1.1 Ceph的核心组件
-
RADOS: 提供对象存储能力,通过将对象划分成小的块,并分布到集群中的多个节点来实现高可用性和可扩展性。可靠、自适应、分布式对象存储
- 可靠性: RADOS以高度可靠性为目标,通过将数据划分为小块,并在整个集群中复制多个副本,以应对硬件故障或节点失效。这确保了数据的冗余存储,提高了系统的容错性。
- 自适应性: RADOS系统具有自适应性,能够根据负载和集群状态自动调整数据的分布和复制策略,以实现负载均衡和性能优化。
- 分布式对象存储: RADOS采用对象存储模型,其中数据被组织为对象并以唯一标识符进行管理。对象存储模型使得Ceph能够有效地存储大规模数据,并提供对这些数据的高性能访问。
-
RBD (RADOS Block Device): 提供块存储服务,允许用户在Ceph集群上创建和管理虚拟机磁盘镜像。 块存储适用于虚拟化环境,提供了高性能的块设备访问。
- 块是一系列字节(通常为512字节)。基于块的存储接口是在包括HDD、SSD、CD、软盘甚至磁带在内的介质上存储数据的一种成熟且常见的方式。块设备接口的普遍性非常适合与包括Ceph在内的大规模数据存储进行交互。
- Ceph块设备是薄配置的、可调整大小的,并将数据条带化存储在多个OSD上。Ceph块设备利用了RADOS的功能,包括快照、复制和强一致性。Ceph块存储客户端通过内核模块或librbd库与Ceph集群通信。

Ceph的块设备通过内核模块或KVM(如QEMU)以及依赖于libvirt和QEMU与Ceph块设备集成的OpenStack、OpenNebula和CloudStack等云计算系统,提供高性能和广阔的可伸缩性。可以同时使用同一集群运行Ceph RADOS Gateway、Ceph文件系统和Ceph块设备。
-
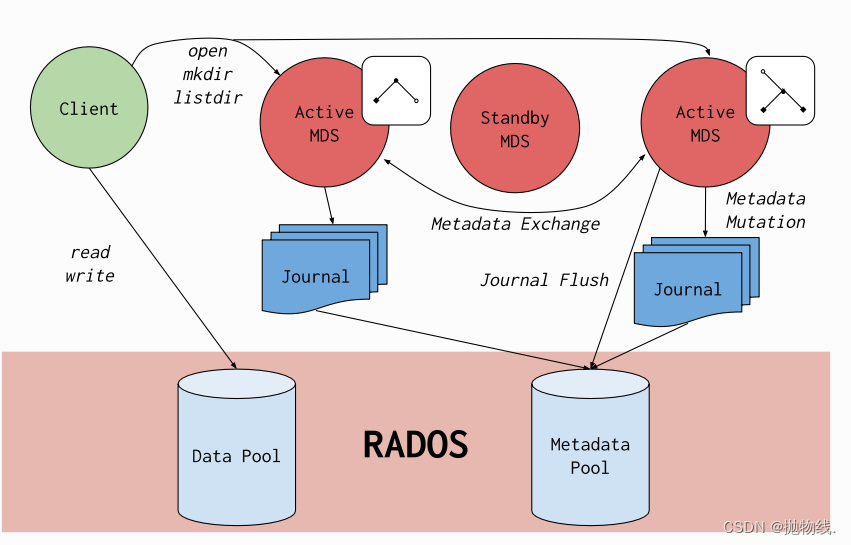
CephFS: CephFS是Ceph提供的分布式文件系统,使用户能够以类似本地文件系统的方式访问存储。这为需要文件系统接口的应用提供了灵活性。
- Ceph文件系统(CephFS)是建立在Ceph分布式对象存储RADOS之上的符合POSIX标准的文件系统。CephFS致力于为各种应用提供一种先进的、多用途的、高可用和高性能的文件存储解决方案,包括传统用例,如共享主目录、HPC临时空间和分布式工作流共享存储。
- 为实现这些目标,CephFS采用了一些创新的架构选择。值得注意的是,文件元数据存储在与文件数据分开的RADOS池中,并通过可调整大小的元数据服务器(Metadata Servers,简称MDS)集群提供服务,该集群可以扩展以支持更高吞吐量的元数据工作负载。文件系统的客户端可以直接访问RADOS以读取和写入文件数据块。因此,工作负载可以与底层RADOS对象存储的大小成比例地线性扩展;换句话说,没有中介或代理用于调解客户端的数据I/O。
- 对数据的访问是通过MDS集群进行协调的,MDS集群充当协同维护的客户端和MDS之间的分布式元数据缓存状态的权威。每个MDS将对元数据的变更汇总为一系列对RADOS上的日志的高效写入;MDS不会在本地存储元数据状态。这种模型允许在POSIX文件系统的上下文中,在客户端之间实现一致而迅速的协作。

CephFS因其创新的设计和对文件系统研究的贡献而成为许多学术论文的研究对象。它是Ceph中最古老的存储接口,曾经是RADOS的主要用例。如今,它与其他两个存储接口共同构成了一个现代化的统一存储系统:RBD(Ceph块设备)和RGW(Ceph对象存储网关)。
1.1.2 Ceph的优势
- 容错性: 数据冗余和自动故障处理使Ceph在硬件故障时能够保持数据的可用性,提高了系统的稳定性。
- 高性能: 通过智能的数据分布和复制策略,Ceph能够实现负载均衡,保证高性能的数据访问。
- 可扩展性: Ceph的设计允许透明地扩展存储集群,以适应不断增长的存储需求。
- 灵活性: 支持多种存储方式,使Ceph适用于各种不同的应用场景。
1.2 自动化运维的需求目标
在大规模和高负载的环境中,手动管理Ceph集群变得愈发复杂且容易出错。以下是生产环境出现的一些手动管理Ceph集群可能面临的挑战:
- 复杂性和规模: 随着存储需求的增加,Ceph集群变得庞大而复杂,手动管理变得繁琐且容易出错。
- 实时性要求: 在高负载环境中,对集群进行实时调整和优化是至关重要的,手动操作无法满足实时性的要求。
- PG负载均衡: 需要对OSD权重、pg负载分布、磁盘利用率、智能数据再平衡、等进行动态调整,以确保集群的负载均衡,手动管理变得耗时且容易忽视忘记甚至对现网误操作,触发重大故障。
- 自动应对故障: 需要能够7*24h自动应对OSD故障、节点故障、磁盘故障、慢盘、产生大量的slow request等各种异常情况,保证集群的稳定性。
- 提供web界面操作: 需要一个直观易用的web界面,使管理员能够方便地监控集群状态、执行操作,例如修改自动化任务的程度频率等定制化需求,降低操作的复杂性和错误的可能性。避免人为错误,确保集群操作的一致性和准确性。
因此,为了应对这些挑战,开发自动化运维平台成为必然选择。这样的平台可以通过智能算法、实时监测和自动化调整,使Ceph集群更具弹性、稳定性和高效性。
2. 平台架构设计和组件版本
2.1 平台架构设计

2.2 组件版本
| 环境 | 版本 | 备注 |
|---|---|---|
| Centos | 7.9 | |
| MongoDB | 3.6.8 | |
| Redis | 6.2.4 | |
| Python | 3.9.17 | |
| Tornado | 6.3.2 | |
| Celery | 5.3.1 | |
| Vue | 3.x | |
| arco design | 2.44.7 | |
| Docker | 19.x + |
-
CentOS 7.9:
- 选择CentOS作为操作系统,这是一个稳定、可靠的Linux发行版,广泛用于服务器环境。版本为7.9,说明系统基于较新的CentOS 7系列。
-
MongoDB 3.6.8:
- MongoDB是一个NoSQL数据库,版本为3.6.8。它被用作后端数据库,可能用于存储系统配置、任务状态等信息。MongoDB的灵活性和可扩展性使其适用于大规模应用。
-
Redis 6.2.4:
- Redis是一种内存数据库,版本为6.2.4。通常用作缓存系统,提供快速的数据读写能力。在自动化运维平台中,Redis可能用于缓存临时数据、任务队列等。
-
Python 3.9.17:
- Python是一种高级编程语言,版本为3.9.17。作为后端的主要编程语言,Python在Web开发和异步任务处理方面具有强大的生态系统。
-
Tornado 6.3.2:
- Tornado是一个Python的异步Web框架,版本为6.3.2。它被用来构建高性能的Web服务器,支持异步I/O,非常适合实时性要求高的应用场景。
-
Celery 5.3.1:
- Celery是一个分布式任务队列,版本为5.3.1。在该架构中,Celery用于处理后台的异步任务,例如集群调整、故障处理等。通过Celery,可以实现高效的任务处理和分布式调度。
-
Vue 3.x:
- Vue是一种现代的JavaScript框架,版本为3.x。在前端开发中,Vue提供了组件化的开发方式,使得前端代码更易于维护和扩展。
-
Arco Design 2.44.7:
- Arco Design是一个基于Vue的UI组件库,版本为2.44.7。它提供了丰富的界面组件,有助于构建美观而功能丰富的用户界面,加速了前端开发的过程。
-
Docker 19.x +:
- Docker用于容器化应用程序,版本为19.x +。Docker可以提供环境隔离和部署的便利性,确保应用在不同环境中具有一致的运行行为。
主要核心逻辑设计:
- 后端 Python3 + Tornado:
Python3作为主要的后端编程语言,支持异步编程,与Tornado框架协同工作,处理Web请求和业务逻辑。 - 前端 Vue3 + Arco Design:
Vue3作为前端框架,构建了用户友好的前端界面。Arco Design提供了一套美观的UI组件,使得前端界面具有现代化的外观和交互。 - 处理模块 Celery:
Celery负责处理后台异步任务,例如自动化调整集群、处理故障等。通过Celery的分布式特性,实现了任务的高效调度和执行。
这个逻辑架构设计强调了后端与前端的协同工作,通过异步任务处理提高了系统的实时性和处理能力。前端使用了Vue3和Arco Design构建直观美观的用户界面,而后端则通过Tornado提供高性能的Web服务。 Celery的引入使得系统能够更好地应对复杂的任务和高并发情况。整体上,这个设计能够应对Ceph集群自动化运维的各种需求。
2.3 模块划分(已经脱敏处理)
2.3.1 当前版本V1.0支持功能
- 单个osd容量超阀值自动处理场景
- 采集集群osd的数据信息用于数据分析
- 采集osd的状态信息用于数据分析
- Request Block场景自动处理
- 自动对因高危场景停止的osd降低权重至x%
- 自动启动解除高危的osd场景(连环形成任务闭环)
- 自动处理单个osd上承载的pg不均衡问题或者数据再均衡
- 监控集群故障域有效性场景
- 监控集群标记是否合理场景
- 监控故障域级别配置是否合理场景
- 监控reweight权重设置异常场景
- 自动对于down状态的osd做降权处理场景
- 自动对于up状态的osd做拉升处理场景
详细解释每个模块的功能,包括:
cluster_capacity_auto.py: 针对单个osd容量超阀值自动处理场景。
collect_osd_datas.py:采集集群osd的数据信息用于数据分析
collect_osd_status.py: 采集osd的状态信息用于数据分析
auto_adjust_osd_weight.py: 动态调整OSD权重的模块。
handle_req_block.py: 集群Request Block场景自动处理
auto_adjust_osd_weight_down.py: 在高负载情况下自动下调OSD权重的模块。
auto_adjust_osd_weight.py: 自动对于up状态的osd做拉升处理场景
…
…
…
2.3.2 前后端代码结构tree图
- 代码结构:

- Dockerfile:
# mmwei3 for 2023/08/06
# Use the official CentOS 7.8.2003 image as the base image
FROM centos:7.8.2003
# Define build-time arguments
ARG PYTHON_VERSION=3.6.8
ARG PIP_VERSION=21.3.1
# Install dependencies and set up yum repository
COPY yum.repos.d/* /etc/yum.repos.d/
RUN rm -rf /etc/yum.repos.d/ && echo 'x.x.x.x' > /etc/resolv.conf && yum makecache fast && \
yum -y install python-rados python-pip redis nginx xdg-utils zlib-devel autoconf automake libtool nasm npm vim ceph python3-devel python3 openssh-server python3-rados zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make libffi-devel vim openssh-server ansible net-tools git openssh-clients ipmitool crontabs wget && \
yum clean all
# Copy project code and configuration files
COPY middleware /home/ceph_manager/middleware
COPY fronted_vue /home/ceph_manager/fronted_vue
COPY nginx.conf /etc/nginx/nginx.conf
# Install Python dependencies and set up pip source
COPY requirements.txt /tmp/
RUN pip3 install --upgrade pip==${PIP_VERSION} && pip3 install -r /tmp/requirements.txt
# Install Python 3.9.17 (if needed)
# COPY Python-3.9.17.tgz /tmp/
# RUN tar -xzvf /tmp/Python-3.9.17.tgz -C /tmp/ && \
# cd /tmp/Python-3.9.17/ && ./configure --enable-optimizations && make altinstall && \
# rm -rf /tmp/Python-3.9.17.tgz /tmp/Python-3.9.17/
# Set npm source and install front-end dependencies
RUN npm config set registry https://registry.npm.taobao.org && \
npm cache clean --force && \
npm install -g @vue/cli --registry=https://registry.npm.taobao.org && \
cd /home/ceph_manager/fronted_vue && npm config set proxy false && npm cache verify && \
npm i -g pnpm && rm -rf node_modules && pnpm install
# Set environment variables and expose ports
ENV LC_ALL=en_US.UTF-8
ENV LANG=en_US.UTF-8
EXPOSE 80
EXPOSE 5173
# Start Nginx
CMD ["nginx", "-g", "daemon off;"]

- 前端tree:
➜ ceph_manager git:(master) ✗ tree fronted_vue -L 3
fronted_vue
├── babel.config.js
├── commitlint.config.js
├── components.d.ts
├── config
│ ├── plugin
│ │ ├── arcoResolver.ts
│ │ ├── arcoStyleImport.ts
│ │ ├── compress.ts
│ │ ├── imagemin.ts
│ │ └── visualizer.ts
│ ├── utils
│ │ └── index.ts
│ ├── vite.config.base.ts
│ ├── vite.config.dev.ts
│ └── vite.config.prod.ts
├── index.html
├── node_modules
│ ├── @arco-design
│ │ └── web-vue -> ../.pnpm/@arco-design+web-vue@2.45.0_vue@3.2.47/node_modules/@arco-design/web-vue
│ ├── @arco-plugins
│ │ └── vite-vue -> ../.pnpm/@arco-plugins+vite-vue@1.4.5/node_modules/@arco-plugins/vite-vue
│ ├── @commitlint
│ │ ├── cli -> ../.pnpm/@commitlint+cli@17.5.1/node_modules/@commitlint/cli
│ │ └── config-conventional -> ../.pnpm/@commitlint+config-conventional@17.4.4/node_modules/@commitlint/config-conventional
│ ├── @eslint
│ │ ├── eslintrc -> ../.pnpm/@eslint+eslintrc@2.0.2/node_modules/@eslint/eslintrc
│ │ └── js -> ../.pnpm/@eslint+js@8.38.0/node_modules/@eslint/js
│ ├── @eslint-community
│ │ ├── eslint-utils -> ../.pnpm/@eslint-community+eslint-utils@4.4.0_eslint@8.38.0/node_modules/@eslint-community/eslint-utils
│ │ └── regexpp -> ../.pnpm/@eslint-community+regexpp@4.5.0/node_modules/@eslint-community/regexpp
│ ├── @types
│ │ ├── eslint -> ../.pnpm/@types+eslint@8.37.0/node_modules/@types/eslint
│ │ ├── lodash -> ../.pnpm/@types+lodash@4.14.192/node_modules/@types/lodash
│ │ ├── mockjs -> ../.pnpm/@types+mockjs@1.0.7/node_modules/@types/mockjs
│ │ ├── nprogress -> ../.pnpm/@types+nprogress@0.2.0/node_modules/@types/nprogress
│ │ └── sortablejs -> ../.pnpm/@types+sortablejs@1.15.1/node_modules/@types/sortablejs
│ ├── @typescript-eslint
│ │ ├── eslint-plugin -> ../.pnpm/@typescript-eslint+eslint-plugin@5.58.0_@typescript-eslint+parser@5.58.0_eslint@8.38.0_typescript@4.9.5/node_modules/@typescript-eslint/eslint-plugin
│ │ ├── parser -> ../.pnpm/@typescript-eslint+parser@5.58.0_eslint@8.38.0_typescript@4.9.5/node_modules/@typescript-eslint/parser
│ │ ├── scope-manager -> ../.pnpm/@typescript-eslint+scope-manager@5.58.0/node_modules/@typescript-eslint/scope-manager
│ │ ├── type-utils -> ../.pnpm/@typescript-eslint+type-utils@5.58.0_eslint@8.38.0_typescript@4.9.5/node_modules/@typescript-eslint/type-utils
│ │ ├── types -> ../.pnpm/@typescript-eslint+types@5.58.0/node_modules/@typescript-eslint/types
│ │ ├── typescript-estree -> ../.pnpm/@typescript-eslint+typescript-estree@5.58.0_typescript@4.9.5/node_modules/@typescript-eslint/typescript-estree
│ │ ├── utils -> ../.pnpm/@typescript-eslint+utils@5.58.0_eslint@8.38.0_typescript@4.9.5/node_modules/@typescript-eslint/utils
│ │ └── visitor-keys -> ../.pnpm/@typescript-eslint+visitor-keys@5.58.0/node_modules/@typescript-eslint/visitor-keys
│ ├── @vitejs
│ │ ├── plugin-vue -> ../.pnpm/@vitejs+plugin-vue@3.2.0_vite@3.2.5_vue@3.2.47/node_modules/@vitejs/plugin-vue
│ │ └── plugin-vue-jsx -> ../.pnpm/@vitejs+plugin-vue-jsx@2.1.1_vite@3.2.5_vue@3.2.47/node_modules/@vitejs/plugin-vue-jsx
│ ├── @vue
│ │ └── babel-plugin-jsx -> ../.pnpm/@vue+babel-plugin-jsx@1.1.1_@babel+core@7.21.4/node_modules/@vue/babel-plugin-jsx
│ ├── @vueuse
│ │ └── core -> ../.pnpm/@vueuse+core@9.13.0_vue@3.2.47/node_modules/@vueuse/core
│ ├── axios -> .pnpm/axios@0.24.0/node_modules/axios
│ ├── consola -> .pnpm/consola@2.15.3/node_modules/consola
│ ├── cross-env -> .pnpm/cross-env@7.0.3/node_modules/cross-env
│ ├── dayjs -> .pnpm/dayjs@1.11.7/node_modules/dayjs
│ ├── echarts -> .pnpm/echarts@5.4.2/node_modules/echarts
│ ├── eslint -> .pnpm/eslint@8.38.0/node_modules/eslint
│ ├── eslint-config-airbnb-base -> .pnpm/eslint-config-airbnb-base@15.0.0_eslint-plugin-import@2.27.5_eslint@8.38.0/node_modules/eslint-config-airbnb-base
│ ├── eslint-config-prettier -> .pnpm/eslint-config-prettier@8.8.0_eslint@8.38.0/node_modules/eslint-config-prettier
│ ├── eslint-import-resolver-node -> .pnpm/eslint-import-resolver-node@0.3.7/node_modules/eslint-import-resolver-node
│ ├── eslint-import-resolver-typescript -> .pnpm/eslint-import-resolver-typescript@3.5.5_@typescript-eslint+parser@5.58.0_eslint-plugin-import@2.27.5_eslint@8.38.0/node_modules/eslint-import-resolver-typescript
│ ├── eslint-module-utils -> .pnpm/eslint-module-utils@2.7.4_@typescript-eslint+parser@5.58.0_eslint-import-resolver-node@0.3.7__fis5gfgpg3bpz5hlprdpm5cuae/node_modules/eslint-module-utils
│ ├── eslint-plugin-import -> .pnpm/eslint-plugin-import@2.27.5_@typescript-eslint+parser@5.58.0_eslint-import-resolver-typescript@3.5.5_eslint@8.38.0/node_modules/eslint-plugin-import
│ ├── eslint-plugin-prettier -> .pnpm/eslint-plugin-prettier@4.2.1_eslint-config-prettier@8.8.0_eslint@8.38.0_prettier@2.8.7/node_modules/eslint-plugin-prettier
│ ├── eslint-plugin-vue -> .pnpm/eslint-plugin-vue@9.10.0_eslint@8.38.0/node_modules/eslint-plugin-vue
│ ├── eslint-scope -> .pnpm/eslint-scope@7.1.1/node_modules/eslint-scope
│ ├── eslint-visitor-keys -> .pnpm/eslint-visitor-keys@3.4.0/node_modules/eslint-visitor-keys
│ ├── husky -> .pnpm/husky@8.0.3/node_modules/husky
│ ├── less -> .pnpm/less@4.1.3/node_modules/less
│ ├── lint-staged -> .pnpm/lint-staged@13.2.1/node_modules/lint-staged
│ ├── lodash -> .pnpm/lodash@4.17.21/node_modules/lodash
│ ├── marked -> .pnpm/registry.npmmirror.com+marked@11.0.0/node_modules/marked
│ ├── mitt -> .pnpm/mitt@3.0.0/node_modules/mitt
│ ├── mockjs -> .pnpm/mockjs@1.1.0/node_modules/mockjs
│ ├── nprogress -> .pnpm/nprogress@0.2.0/node_modules/nprogress
│ ├── pinia -> .pnpm/pinia@2.0.34_typescript@4.9.5_vue@3.2.47/node_modules/pinia
│ ├── postcss-html -> .pnpm/postcss-html@1.5.0/node_modules/postcss-html
│ ├── prettier -> .pnpm/prettier@2.8.7/node_modules/prettier
│ ├── prettier-linter-helpers -> .pnpm/prettier-linter-helpers@1.0.0/node_modules/prettier-linter-helpers
│ ├── query-string -> .pnpm/query-string@8.1.0/node_modules/query-string
│ ├── rollup -> .pnpm/rollup@2.79.1/node_modules/rollup
│ ├── rollup-plugin-visualizer -> .pnpm/rollup-plugin-visualizer@5.9.0_rollup@2.79.1/node_modules/rollup-plugin-visualizer
│ ├── sortablejs -> .pnpm/sortablejs@1.15.0/node_modules/sortablejs
│ ├── stylelint -> .pnpm/stylelint@14.16.1/node_modules/stylelint
│ ├── stylelint-config-prettier -> .pnpm/stylelint-config-prettier@9.0.5_stylelint@14.16.1/node_modules/stylelint-config-prettier
│ ├── stylelint-config-rational-order -> .pnpm/stylelint-config-rational-order@0.1.2/node_modules/stylelint-config-rational-order
│ ├── stylelint-config-recommended-vue -> .pnpm/stylelint-config-recommended-vue@1.4.0_postcss-html@1.5.0_stylelint@14.16.1/node_modules/stylelint-config-recommended-vue
│ ├── stylelint-config-standard -> .pnpm/stylelint-config-standard@29.0.0_stylelint@14.16.1/node_modules/stylelint-config-standard
│ ├── stylelint-order -> .pnpm/stylelint-order@5.0.0_stylelint@14.16.1/node_modules/stylelint-order
│ ├── typescript -> .pnpm/typescript@4.9.5/node_modules/typescript
│ ├── unplugin-vue-components -> .pnpm/unplugin-vue-components@0.24.1_rollup@2.79.1_vue@3.2.47/node_modules/unplugin-vue-components
│ ├── vite -> .pnpm/vite@3.2.5_@types+node@18.15.11_less@4.1.3/node_modules/vite
│ ├── vite-plugin-compression -> .pnpm/vite-plugin-compression@0.5.1_vite@3.2.5/node_modules/vite-plugin-compression
│ ├── vite-plugin-eslint -> .pnpm/vite-plugin-eslint@1.8.1_eslint@8.38.0_vite@3.2.5/node_modules/vite-plugin-eslint
│ ├── vite-plugin-imagemin -> .pnpm/vite-plugin-imagemin@0.6.1_vite@3.2.5/node_modules/vite-plugin-imagemin
│ ├── vite-svg-loader -> .pnpm/vite-svg-loader@3.6.0/node_modules/vite-svg-loader
│ ├── vue -> .pnpm/vue@3.2.47/node_modules/vue
│ ├── vue-echarts -> .pnpm/vue-echarts@6.5.4_echarts@5.4.2_vue@3.2.47/node_modules/vue-echarts
│ ├── vue-eslint-parser -> .pnpm/vue-eslint-parser@9.1.1_eslint@8.38.0/node_modules/vue-eslint-parser
│ ├── vue-i18n -> .pnpm/vue-i18n@9.2.2_vue@3.2.47/node_modules/vue-i18n
│ ├── vue-router -> .pnpm/vue-router@4.1.6_vue@3.2.47/node_modules/vue-router
│ └── vue-tsc -> .pnpm/vue-tsc@1.2.0_typescript@4.9.5/node_modules/vue-tsc
├── package-lock.json
├── package.json
├── pnpm-lock.yaml
├── src
│ ├── App.vue
│ ├── api
│ │ ├── dashboard.ts
│ │ ├── form.ts
│ │ ├── interceptor.ts
│ │ ├── list.ts
│ │ ├── message.ts
│ │ ├── profile.ts
│ │ ├── storage.ts
│ │ ├── task.ts
│ │ ├── user-center.ts
│ │ ├── user.ts
│ │ └── visualization.ts
│ ├── assets
│ │ ├── images
│ │ ├── img.png
│ │ ├── logo.svg
│ │ ├── style
│ │ └── world.json
│ ├── components
│ │ ├── breadcrumb
│ │ ├── chart
│ │ ├── footer
│ │ ├── global-setting
│ │ ├── index.ts
│ │ ├── menu
│ │ ├── message-box
│ │ ├── navbar
│ │ └── tab-bar
│ ├── config
│ │ └── settings.json
│ ├── directive
│ │ ├── index.ts
│ │ └── permission
│ ├── env.d.ts
│ ├── hooks
│ │ ├── chart-option.ts
│ │ ├── loading.ts
│ │ ├── locale.ts
│ │ ├── permission.ts
│ │ ├── request.ts
│ │ ├── responsive.ts
│ │ ├── themes.ts
│ │ ├── user.ts
│ │ └── visible.ts
│ ├── layout
│ │ ├── default-layout.vue
│ │ └── page-layout.vue
│ ├── locale
│ │ ├── en-US
│ │ ├── en-US.ts
│ │ ├── index.ts
│ │ ├── zh-CN
│ │ └── zh-CN.ts
│ ├── main.ts
│ ├── mock
│ │ ├── index.ts
│ │ ├── message-box.ts
│ │ └── user.ts
│ ├── router
│ │ ├── app-menus
│ │ ├── constants.ts
│ │ ├── guard
│ │ ├── index.ts
│ │ ├── routes
│ │ └── typings.d.ts
│ ├── store
│ │ ├── index.ts
│ │ └── modules
│ ├── types
│ │ ├── echarts.ts
│ │ ├── global.ts
│ │ └── mock.ts
│ ├── utils
│ │ ├── auth.ts
│ │ ├── env.ts
│ │ ├── event.ts
│ │ ├── index.ts
│ │ ├── is.ts
│ │ ├── monitor.ts
│ │ ├── route-listener.ts
│ │ └── setup-mock.ts
│ └── views
│ ├── dashboard
│ ├── exception
│ ├── form
│ ├── list
│ ├── login
│ ├── not-found
│ ├── profile
│ ├── redirect
│ ├── result
│ ├── storage
│ ├── task
│ ├── user
│ └── visualization
├── tsconfig.json
└── yarn.lock
135 directories, 70 files
➜ ceph_manager git:(master) ✗
- 后端tree:
➜ ceph_manager git:(master) ✗ tree middleware -L 3
middleware
├── __init__.py
├── base.py
├── cephAuto.py
├── config
│ ├── ceph.yaml
│ ├── common.yaml
│ ├── logger.yaml
│ ├── monitor.yaml
│ └── scheduler.yaml
├── conn
│ ├── __init__.py
│ ├── mongo.py
│ └── rediscon.py
├── logger.py
├── monitor.py
├── scheduler.py
├── start_celery.sh
├── tasks
│ ├── __init__.py
│ ├── auto_adjust_osd_weight.py
│ ├── auto_adjust_osd_weight_down.py
│ ├── auto_adjust_osd_weight_stop_pools.py
│ ├── auto_crush_down_alike.py
│ ├── auto_start_osd_stop_pools.py
│ ├── ceph_cluster_flags.py
│ ├── ceph_reweight_zero.py
│ ├── check_crush_rule.py
│ ├── cluster_capacity_auto.py
│ ├── collect_osd_datas.py
│ ├── collect_osd_status.py
│ ├── data_rebalancing.py
│ ├── handle_req_block.py
│ ├── handler_task_result.py
│ └── pr_str1.py
├── test
│ ├── __init__.py
│ ├── test_ceph_utils.py
│ ├── test_logger.py
│ └── test_send_sms.py
├── utils
│ ├── __init__.py
│ ├── ceph_util.py
│ ├── config_task.py
│ ├── dashboard.py
│ ├── mongo_crud.py
│ ├── osd_datas_handler.py
│ ├── send_sms.py
│ ├── storage_osd.py
│ └── test_req.py
└── worker.py
5 directories, 45 files
➜ ceph_manager git:(master) ✗
2.3.3 工作流程
平台的整体工作流程涉及多个模块的协同工作和数据流,下面对其进行详细说明。
- 用户请求接收:
工作流的起点是用户通过Web界面发起登录请求。这可以是关于集群状态查询、调整集群任务时间、故障处理等各种操作。 - Tornado Web服务器处理请求:
用户的请求首先由Tornado Web服务器接收和处理。Tornado是一个异步Web框架,能够高效地处理大量并发请求。它负责路由用户请求到相应的处理模块。 - Celery异步任务调度:
部分用户请求可能涉及到耗时的任务,比如自动调整集群OSD权重、PG均衡等。为了不阻塞Web服务器,这些任务被异步地提交给Celery任务队列。 - Celery Worker执行任务:
Celery Worker负责从任务队列中获取任务,并在后台执行。这些任务包括Ceph集群的自动调整、故障处理等,涉及到与Ceph集群交互的复杂逻辑。 - MongoDB和Redis数据存储:
在任务执行的过程中,可能需要存储和检索一些临时数据。MongoDB用于存储系统配置、任务状态等信息,而Redis则用作缓存系统,提高一些数据的读写速度。 - 任务结果反馈给前端:
任务执行完成后,系统将任务执行的结果反馈给前端。这包括操作是否成功、详细的任务日志、可能的异常信息等。用户可以通过Web界面实时查看任务的执行状态。 - Vue和Arco Design呈现数据:
前端使用Vue框架构建用户界面,并借助Arco Design的UI组件提供良好的用户体验。通过数据交互,前端将用户请求的结果以直观的方式呈现给用户。 - 用户交互和反馈:
用户通过Web界面与平台进行交互,可以查看集群状态、发起操作请求、查看任务执行日志等。系统的实时性和用户友好性通过这一步得以展现。
整体而言,工作流程实现了前后端的协同工作,使得用户能够通过Web界面方便地对Ceph集群进行各种操作,而后端则通过异步任务的方式实现了高并发和复杂任务的处理。 Celery任务队列、MongoDB、Redis等组件相互协作,构成了一个高效、可扩展的自动化运维平台。
2.3.4 模块算法和处理逻辑(举几个典型场景)
2.3.4.1 自动对因高危场景停止的osd降低权重至x%
-
逻辑图:

-
自动对因高危场景停止的osd降低权重至75%
如上图自动化处理逻辑流程所示: -
ceph_manager组件根据设置的定时任务,会轮询触发celery task。
- 首先会检测集群是否存在noout标志,如果存在该标志,则说明集群处于人为介入的维护状态,暂时不做自动处理,worker任务结束。
- 如果集群不是出于noout标志,则会进入筛选器,筛选条件有两个:
- 第一个条件:会从特定的mongodb库中找到对应的status状态的osd,默认是status=1状态(该数据来源于异常的阀值的osd)。
- 第二个条件:判断该磁盘大小是否符合配置要求,比如配置中心已经做了配置该流程仅把磁盘大小为6TB以上的盘做为处理目标。 - 根据筛选器筛选的结果,进行判断处理,若筛选池为空,则结束本次worker任务。
- 若筛选器筛选出结果后,会对其做优先级设置,(优先级:根据mongodb.osd.stop_pool中status=1的插入时间最早原则,时间越早,优先级最高)。 然后筛选出最高优先级的一个osd。
- 判断集群是否出于error状态,如果是error状态,则结束本次worker任务。
- 若集群出于非error状态,则根据异常osd停止前时插入的osd信息,判断当前集群中的osd的crush weight值和当时写入的target crush weight值做大小判断:
- 如果当前值小于目标值,则说明需要进行权重调整处理,这里调整逻辑默认为每次0.05(可以配置)。
- 若当前值不小于目标值,则说明不需要调整,即将该条osd的信息状态在mongodb进行更新,告诉该场景任务下该osd已经进入该场景的半闭环状态,剩余的最后闭环会在另一个场景中实现。
- task代码:
考虑到多线程安全,所以mongodb的链接全部独立
#!/usr/bin/python
# -*- coding: utf-8 -*-
# auto: mmwei3
# date: 2023/08/25
import os
import re
from datetime import datetime
from pymongo import MongoClient, UpdateOne
from celery import current_task, Celery
from celery.result import AsyncResult
from utils.ceph_util import CephUtils
from logger import get_logger
from utils.send_sms import SendSms
from scheduler import app
class Config:
"""
Configuration class to manage settings.
"""
def __init__(self):
self.logger = get_logger()
self.ceph = CephUtils(config_file='/home/ceph_manager/middleware/config/ceph.yaml')
file_path = os.path.abspath(os.path.join(os.path.dirname(__file__), "../config/common.yaml"))
with open(file_path) as f:
self.config = yaml.safe_load(f)
self.uri = self.config["mongodb"]["mongodb_uri"]
self.sms = SendSms(config_file='/home/ceph_manager/middleware/config/monitor.yaml')
def extract_number_from_string(self, s):
match = re.search(r'@(\d+)', s)
return int(match.group(1)) if match else None
config = Config()
def log_result(func):
"""
Decorator to log task results and insert them into MongoDB.
Args:
func (callable): The function to be decorated.
Returns:
callable: The wrapped function.
"""
def wrapper(*args, **kwargs):
result_message, effect = func(*args, **kwargs)
mgdb = MongoClient(config.uri).ceph
task_id = current_task.request.id
result_obj = AsyncResult(task_id)
task_status = result_obj.status
config.logger.info(f"Task ID {task_id} status: {task_status}")
cluster_name, cluster_cname = config.ceph.cluster_name, config.ceph.cluster_cname
mg_data = {'status': 1, 'create_time': datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
'name': 'cluster_capacity_auto', 'result': result_message, 'task_id': task_id,
'is_effect': effect, 'task_status': task_status, 'cluster_name': cluster_name,
'cluster_cname': cluster_cname, 'task_type': 'Automatic Processing',
'uname': 'Capacity Threshold Automatic Processing Scene'}
mgdb.tasks.insert_one(mg_data)
config.logger.info(result_message)
return result_message
return wrapper
@log_result
def insert_osd_pool(osd_name, osd_reweight):
"""
Insert OSD pool data into MongoDB.
Args:
osd_name (str): Name of the OSD.
osd_reweight (float): Reweight value of the OSD.
"""
target_osd_reweight = float(osd_reweight / 1.5)
mgdb = MongoClient(config.uri).ceph
data = {'status': 1, 'create_time': datetime.now().strftime("%Y-%m-%d %H:%M:%S"), 'name': osd_name,
'crush_weight': osd_reweight, 'target_osd_reweight': target_osd_reweight,
'oid': config.extract_number_from_string(osd_name)}
update_operation = UpdateOne({'name': osd_name}, {'$set': data}, upsert=True)
result = mgdb.stop_osd_pool.bulk_write([update_operation])
if result.upserted_count > 0:
config.logger.info(f"Inserted OSD pool data for osd_name: {osd_name}")
else:
config.logger.info(f"OSD pool data for osd_name: {osd_name} already exists. Skipping insertion.")
@app.task
@log_result
def cluster_capacity_auto():
"""
Automatic processing of storage cluster capacity.
Returns:
tuple: A tuple containing the result message and the effect flag.
"""
cluster_status = config.ceph.get_cluster_status()
cluster_name, cluster_cname = config.ceph.cluster_name, config.ceph.cluster_cname
if 'HEALTH_ERROR' not in cluster_status:
exec_result, osd_name, osd_host_ip, osd_host, osd_crush, result_message, osd_reweight = config.ceph.stop_osd_services()
if exec_result != 'null':
result_message = (f'Automatically stopped OSD with high capacity, Cluster: {cluster_name} {cluster_cname}, '
f'Name: {osd_name}, IP: {osd_host_ip}, Host: {osd_host}, Crush: {osd_crush}, '
f'Execution Status: {exec_result}')
insert_osd_pool(osd_name, osd_reweight)
sms_subject = 'CEPH Storage Cluster Threshold Exceeded - Automatic Processing'
config.sms.send_email(sms_subject, str(result_message))
effect = 1
else:
result_message = result_message
effect = 0
else:
result_message = f'Storage Cluster ERROR: {cluster_name} {cluster_cname}'
config.sms.send_sms(result_message)
sms_subject = 'CEPH Storage Cluster ERROR'
config.sms.send_email(sms_subject, str(result_message))
effect = 0
return result_message, effect
2.3.4.2 Request Block场景自动处理
-
逻辑图:

-
ceph request block 场景自动处理
如上图自动化处理逻辑流程所示:
-
ceph_manager组件根据设置的定时任务,会轮询触发celery task。
-
首先会开启检测集群是否出现req block:
- 如果没有出现req block则worker任务结束;
- 如果出现req block,则进入筛选器:
-
第一个条件:block是否持续xs(可以配置);
-
第二个条件:block数量是否大于y个(可以配置)。
-
若不满足该筛选器,则发送邮件及短信:说明未调整的原因,本次worker任务结束。
-
若满足筛选器,则进行自动调整操作,调整内容:
- 对出现req block的osd进行排序,定位最高的一次的osd,并判断该osd同一个crush下是否存在已经down的超过两个的节点:
- 若超过:则发送邮件及短信:说明未调整的原因,本次worker任务结束。
- 若未超过:则进行stop目标节点的osd target服务,之后进行集群状态检测(通过sleep z 秒) z可以配置,其后发送已经调整的邮件及短信,本次worker任务结束。
- task代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
# auto: mmwei3
# date: 2023/08/25
from utils.ceph_util import CephUtils
from utils.send_sms import SendSms
from scheduler import app
from logger import get_logger
from pymongo import MongoClient
from celery import current_task
from celery.result import AsyncResult
from datetime import datetime
import re
import time
import json
logger = get_logger()
ceph = CephUtils(config_file='/home/ceph_manager/middleware/config/ceph.yaml')
file_path = os.path.abspath(
os.path.join(os.path.dirname(__file__), "../config/common.yaml")
)
with open(file_path) as f:
config = yaml.safe_load(f)
uri = config["mongodb"]["mongodb_uri"]
sms = SendSms(config_file='/home/ceph_manager/middleware/config/monitor.yaml')
def read_local_json(file_path):
"""
Method to read JSON data from a local file.
:param file_path: Path to the JSON file
:return: Parsed JSON data
"""
with open(file_path, 'r') as json_file:
return json.load(json_file)
def process_and_sort_data(data_list):
"""
Method to process and sort data.
:param data_list: List of data to be processed
:return: Sorted and filtered data list, and the last osd in the element with the highest ops blocked
"""
filtered_data = [item for item in data_list if "ops are blocked" in item]
sorted_data = sorted(filtered_data, key=lambda x: int(re.search(r'(\d+) ops are blocked', x).group(1)),
reverse=True)
return re.search(r'(\S+)$', sorted_data[0]).group(1)
def wait_and_refresh_data():
"""
Method to wait for 30 seconds and refresh data.
:return: Tuple of summary and detail data
"""
time.sleep(30)
return ceph.get_health_detail()["summary"], ceph.get_health_detail()["detail"]
def handle_blocked_requests():
"""
Function to handle the scenario of a large number of request blocks in the Ceph cluster.
It checks the cluster's health status and takes action if a large number of requests are blocked.
:return: Tuple of result message and effect flag
"""
cluster_block = ceph.cluster_block
summary, detail = ceph.get_health_detail()["summary"], ceph.get_health_detail()["detail"]
result_message, effect = "No relevant messages", 0
def set_effect_message(new_effect, new_result_message):
"""
Helper function to set effect and result_message.
:param new_effect: New effect value
:param new_result_message: New result message
"""
nonlocal effect, result_message
effect, result_message = new_effect, new_result_message
for item in summary:
if "requests are blocked" not in item.get("summary", ""):
set_effect_message(0, "The cluster has no blocked requests, the cluster is in a normal state.")
continue
blocked_count = int(item["summary"].split(" ")[0])
if blocked_count <= int(cluster_block):
set_effect_message(0, "The number of blocked requests is within the threshold, the cluster is in a normal state.")
continue
logger.info(f"Blocked request count continues to increase. Sleep time: 30 seconds")
new_summary, new_detail = wait_and_refresh_data()
new_blocked_count = sum(
int(new_item["summary"].split(" ")[0]) for new_item in new_summary if
"requests are blocked" in new_item.get("summary", "")
)
if new_blocked_count <= int(cluster_block):
set_effect_message(0, "Blocked request count continues to increase, waiting for the delay period to elapse.")
else:
set_effect_message(1, "")
highest_ops_blocked_osd = process_and_sort_data(new_detail)
osd_name = highest_ops_blocked_osd
logger.info('osd_name is : ')
logger.info(osd_name)
exec_result, osd_name, osd_host_ip, osd_host, osd_crush, result_message = ceph.stop_target_services(osd_name)
ceph.set_cluster_noout()
if exec_result != 'null':
result_message = (
f'Automatically stopped OSD with high request block count, '
f'Cluster: {ceph.cluster_name} {ceph.cluster_cname}, '
f'IP: {osd_host_ip}, Host: {osd_host}, Crush: {osd_crush}, '
f'Execution Status: {exec_result}'
)
logger.info(result_message)
sms.send_sms(result_message)
sms_subject = 'CEPH Cluster OSD Auto-Stop due to High Request Blocks'
sms.send_email(sms_subject, str(result_message))
else:
result_message = result_message
return result_message, effect
@app.task
def handle_req_block():
"""
Celery task to handle blocked requests in the Ceph cluster.
"""
return handle_blocked_requests()
2.3.4.3 单个osd容量超阀值自动处理场景
- 逻辑设计:

- ceph集群单个osd容量超93%自动处理场景说明:
如上图自动化处理逻辑流程所示:
- ceph_manager组件根据设置的定时任务,会轮询触发celery task。
- 该任务发起时,首先会检查该集群中是否存在单个osd使用容量超过93%的,如果不存在,则本次task流程worker任务结束,等待下一次重新发起。
- 若检测发现该集群存在单个osd容量超过93%,则触发筛选器进行筛选,两个条件:
- 第一个:集群异常的osd数量,与集群自定义允许down的配置数量对比,比如集群无论多少节点,无论多少副本,则最多允许down10个osd,那么第一个条件就是检测是否已经down了10个osd.
- 第二个条件检测单个crush下的已经down的osd数量(crush_weight不等于0)
- 若筛选器发现不满足第3条中的两个硬性条件,则发生未调整的告警短信及告警邮件以及未触发自动调整的原因(告警邮件及短信格式:会包含集群名称,region名称,最高的osd名称及节点名称,及原因),并且结束本次worker任务,等待下一次重新发起。
- 若筛选器发现满足第3条中的两个硬性条件,则触发自动调整操作:(前提默认该集群的阀值以及设置到0.95)会停止这个异常的osd,并且向mongodb的特定的数据库表中插入一条数据,数据主要是当前osd的信息以及附加的一个target crush weight的值及记录状态,主要用于集群中其他的自动化任务识别到该异常的osd后会按照这个目标权重进行调整直至解除危险并成功拉起这个osd,做到单挑任务链闭环。
- task代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
# auto: mmwei3
# date: 2023/08/25
import subprocess
from utils.ceph_util import CephUtils
from logger import get_logger
from scheduler import app
from typing import Optional, Tuple, Any
import os
import yaml
from datetime import datetime
from pymongo import MongoClient
from celery import current_task
from celery.result import AsyncResult
logger = get_logger()
ceph = CephUtils(config_file='/home/ceph_manager/middleware/config/ceph.yaml')
# Use context manager for file handling
with open(os.path.abspath(os.path.join(os.path.dirname(__file__), "../config/common.yaml"))) as f:
config = yaml.safe_load(f)
uri = config["mongodb"]["mongodb_uri"]
@app.task
def auto_adjust_osd_weight_stop_pools():
"""
This task adjusts OSD weights for down OSDs and processes duplicate hostnames.
:return: None
"""
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
def process_cluster_info(osds_hight_target, current_crush_weight, cluster_status, osd_weight_step):
"""
Process information related to adjusting OSD weights based on the cluster status.
:param osds_hight_target: Target OSD information
:param current_crush_weight: Current crush weight of the OSD
:param cluster_status: Current status of the Ceph cluster
:param osd_weight_step: Step for adjusting OSD weight
:return: Result message after adjusting OSD weight
"""
if osds_hight_target and current_crush_weight:
if 'HEALTH_ERROR' not in cluster_status:
effect = 1
next_crush_weight = current_crush_weight - osd_weight_step
if next_crush_weight > osds_hight_target['target_osd_reweight']:
logger.info('Starting OSD weight DOWN adjustment...for stop pools')
osds_hight_target['id'] = osds_hight_target['name'].split('@')[-1]
set_osd_crush_weight = (
ceph.set_osd_crush_weight(osds_hight_target['id'], 0)
if current_crush_weight < osd_weight_step
else ceph.set_osd_crush_weight(osds_hight_target['id'], next_crush_weight)
)
result_message = (
f"Adjusting OSD DOWN weight successful for osd_name: {osds_hight_target['name']} "
f"to crush_weight: {next_crush_weight}, OSD weight adjustment completed."
if set_osd_crush_weight
else f"Adjusting OSD DOWN weight failed for osd_name: {osds_hight_target['name']} "
f"to crush_weight: {next_crush_weight}, OSD weight adjustment exec failed."
)
else:
mgdb = MongoClient(uri).ceph
mgdb.stop_osd_pool.update_one(
{'name': osds_hight_target['name']},
{'$set': {'status': 0, 'update_time_reduce_complete': current_time}}
)
result_message = (
f"The osd {osds_hight_target['name']} weight has been adjusted to 75%, "
f"{next_crush_weight} of the original. OSD weight down adjustment aborted."
)
else:
effect = 0
result_message = 'Cluster status is not OK. OSD weight down adjustment aborted.'
else:
effect = 0
result_message = 'There are no down status osd weight needs to be reduce.. OSD weight down adjustment aborted.'
log_and_insert_result(result_message, effect)
return result_message
def log_and_insert_result(result_message: str, effect):
"""
Log the result and insert it into the MongoDB database.
:param result_message: Result message to be logged and inserted
:param effect: Effect flag indicating success or failure
:return: None
"""
mgdb = MongoClient(uri).ceph
task_id = current_task.request.id
result_obj = AsyncResult(task_id)
task_status = result_obj.status
logger.info(f"Task ID {task_id} status: {task_status}")
cluster_name = ceph.cluster_name
cluster_cname = ceph.cluster_cname
# task_status_flag is 0: wait update task status filed; 1 already update task status filed
mg_data = {'status': 1, 'create_time': current_time, 'name': 'auto_adjust_osd_weight_stop_pools',
'result': result_message,
'task_id': task_id, 'is_effect': effect, 'task_status': task_status, 'cluster_name': cluster_name,
'cluster_cname': cluster_cname, 'task_type': '自动处理', 'uname': '自动对因高危场景停止的osd降低权重至75%'}
mgdb.tasks.insert_one(mg_data)
logger.info(result_message)
osd_weight_step_stop_pools = ceph.osd_weight_step_stop_pools
cluster_status = ceph.get_cluster_status()
mgdb = MongoClient(uri).ceph
stop_osd_pools = list(mgdb.stop_osd_pool.find({'status': {"$eq": 1}}))
sorted_stop_osd_pools = sorted(
stop_osd_pools,
key=lambda x: datetime.strptime(x['create_time'], '%Y-%m-%d %H:%M:%S'),
reverse=True
)
logger.info('sorted_stop_osd_pools:')
logger.info(sorted_stop_osd_pools)
# Use the walrus operator to avoid calling `sorted_stop_osd_pools[0]` twice
if first_entry := next(iter(sorted_stop_osd_pools), None):
crush_id = first_entry['name'].split('@')[-1]
current_crush_weight = ceph.get_osd_crush_weight(crush_id)
else:
current_crush_weight = None
datas = ceph.get_cluster_detail()
if not datas:
result_message = 'Get cluster info is failed. OSD weight down adjustment aborted.'
log_and_insert_result(result_message, 0)
return result_message
# Check for blocked requests in the cluster
summary = datas.get("health", {}).get("summary", [])
try:
if not summary or len(summary) == 0:
result_message = process_cluster_info(first_entry, current_crush_weight, cluster_status,
osd_weight_step_stop_pools)
else:
for item in summary:
if "noout" in item.get("summary", ""):
effect = 0
result_message = 'Cluster status is noout. OSD weight down adjustment aborted.'
break
else:
effect = 0
result_message = process_cluster_info(first_entry, current_crush_weight, cluster_status,
osd_weight_step_stop_pools)
except (subprocess.CalledProcessError, ValueError) as e:
result_message = f"Failed to get cluster status: {e}"
log_and_insert_result(result_message, 0)
return result_message
else:
log_and_insert_result(result_message, effect)
return result_message
2.3.4.4 自动对于down状态的osd做降权处理场景
- 逻辑设计:
 - 对于down状态的osd做降权处理场景
- 对于down状态的osd做降权处理场景
如上图自动化处理逻辑流程所示:
-
ceph_manager组件根据设置的定时任务,会轮询触发celery task。
-
首先会判断集群是否处于noout状态,若处于noout状态(默认为人工介入维护状态),则本次worker任务结束。
-
若未处于noout状态,则进入筛选器开始筛选:
- 筛选状态为UP的down; - osd的状态为out -
osd不在mongodb中特定的库中(因其他原因如阀值,停止的osd插入到mongodb中的)
-
磁盘大小符合配置要求,(可以根据需求选择调整多大容量的盘)
-
osd的crush weight不为0,reweight不为0.
-
若筛选器筛选的符合要求的osd为空,则本次worker任务结束。
-
若筛选器筛选的符合要求的osd为非空,则筛选优先级最高的1个osd进行调整(优先级:根据同一个host下的down的osd数量最少原则,优先级越高):
- 调整之前检测集群是否error,如果error则本次worker任务结束;
- 若集群未处于error状态,则进行降低crush weight调整操作,默认每次0.05(可配置),本次worker任务结束。
task代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
# auto: mmwei3
# date: 2023/08/25
import logging
import subprocess
from utils.ceph_util import CephUtils
from logger import get_logger
from scheduler import app
from typing import Optional, Tuple, Any
import os
import yaml
from datetime import datetime
from pymongo import MongoClient
from celery import current_task
from celery.result import AsyncResult
logger = get_logger()
ceph = CephUtils(config_file='/home/ceph_manager/middleware/config/ceph.yaml')
# Use context manager for file handling
with open(os.path.abspath(os.path.join(os.path.dirname(__file__), "../config/common.yaml"))) as f:
config = yaml.safe_load(f)
uri = config["mongodb"]["mongodb_uri"]
def filter_duplicate_osds(eligible_osds, stop_osd_pools):
# Extract the names of OSDs from stop_osd_pools
existing_osd_names = {entry['name'].replace('ceph-', '').replace('@', '.') for entry in stop_osd_pools}
logger.info('existing_osd_names:')
logger.info(existing_osd_names)
# Filter out OSDs from eligible_osds that are already in stop_osd_pools
filtered_eligible_osds = [osd for osd in eligible_osds if osd['name'] not in existing_osd_names]
return filtered_eligible_osds
def calculate_target_crush_weight(osd_data) -> Optional[Any]:
"""
Calculate the target crush weight for eligible down OSDs.
:param osd_data: OSD data
:return: List of dictionaries with OSD counts for duplicate hostnames
"""
osds_below_targets = []
mgdb = MongoClient(uri).ceph
stop_osd_pools = list(mgdb.stop_osd_pool.find({'status': {"$eq": 1}}))
logger.info('stop_osd_pools: ')
logger.info(stop_osd_pools)
for osd in osd_data:
if osd["type"] == "osd" and osd['status'] == 'down' and osd['reweight'] < 0.1:
# Calculate the target weight based on size 0
target_weight = 0
# Check if the difference between current OSD's crush_weight and target_weight is greater than 0.2
if osd["crush_weight"] > target_weight:
osd.update({'target_weight': target_weight})
osds_below_targets.append(osd)
# Use the filter_duplicate_osds function to get the filtered list
logger.info('osds_below_targets:')
logger.info(osds_below_targets)
osds_below_target = filter_duplicate_osds(osds_below_targets, stop_osd_pools)
if osds_below_target:
logger.info("osds_below_target: ")
logger.info(osds_below_target)
osds_below_target_down = process_duplicate_hostnames(osds_below_target)
logger.info("osds_below_target_down: ")
logger.info(osds_below_target_down)
osds_hight_id = osds_below_target_down[0]['osd_id'][0]
current_osd_crush_weight = ceph.get_osd_crush_weight(osds_hight_id)
tmp_datas = {'crush_weight': current_osd_crush_weight, 'id': osds_hight_id}
return tmp_datas
else:
return None
def process_duplicate_hostnames(osds_below_target) -> list:
"""
Process duplicate hostnames and count OSDs with the same hostname.
:param osds_below_target: List of OSDs below target
:return: List of dictionaries with OSD counts for duplicate hostnames
"""
# Create a dictionary to store the count of each hostname
hostname_count = {}
# Populate the hostname_count dictionary
for osd in osds_below_target:
hostname = osd['hostname']
if hostname in hostname_count:
hostname_count[hostname]['osd_id'].append(osd['id'])
hostname_count[hostname]['count'] += 1
else:
hostname_count[hostname] = {'osd_id': [osd['id']], 'count': 1}
# Convert the dictionary values to a list
duplicate_hostnames = list(hostname_count.values())
# Sort duplicate_hostnames by 'count' in ascending order
duplicate_hostnames = sorted(duplicate_hostnames, key=lambda x: x['count'])
return duplicate_hostnames
@app.task
def auto_adjust_osd_weight_down():
"""
This task adjusts OSD weights for down OSDs and processes duplicate hostnames.
:return: None
"""
def process_cluster_info(osds_hight_target, cluster_status, osd_weight_step):
if osds_hight_target:
if 'HEALTH_ERROR' not in cluster_status:
effect = 1
next_crush_weight = osds_hight_target['crush_weight'] - osd_weight_step
if osds_hight_target['crush_weight'] < osd_weight_step:
set_osd_crush_weight = ceph.set_osd_crush_weight(osds_hight_target['id'], 0)
else:
logger.info('Starting OSD weight DOWN adjustment...1')
logger.info(osds_hight_target)
set_osd_crush_weight = ceph.set_osd_crush_weight(osds_hight_target['id'], next_crush_weight)
if set_osd_crush_weight:
result_message = f"Adjusting OSD DOWN weight successful for osd_name: {osds_hight_target['id']} to crush_weight: {next_crush_weight}, OSD weight adjustment completed."
else:
result_message = f"Adjusting OSD DOWN weight failed for osd_name: {osds_hight_target['id']} to crush_weight: {next_crush_weight}, OSD weight adjustment exec failed."
else:
effect = 0
result_message = 'Cluster status is not OK. OSD weight down adjustment aborted.'
else:
effect = 0
result_message = 'There are no down status osd weight needs to be reduce.. OSD weight down adjustment aborted.'
log_and_insert_result(result_message, effect)
return result_message
def log_and_insert_result(result_message: str, effect):
mgdb = MongoClient(uri).ceph
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
task_id = current_task.request.id
result_obj = AsyncResult(task_id)
task_status = result_obj.status
logger.info(f"Task ID {task_id} status: {task_status}")
cluster_name = ceph.cluster_name
cluster_cname = ceph.cluster_cname
# task_status_flag is 0: wait update task status filed; 1 already update task status filed
mg_data = {'status': 1, 'create_time': current_time, 'name': 'auto_adjust_osd_weight_down',
'result': result_message,
'task_id': task_id, 'is_effect': effect, 'task_status': task_status, 'cluster_name': cluster_name,
'cluster_cname': cluster_cname, 'task_type': '自动处理', 'uname': '对于down状态的osd做降权处理场景'}
# Insert data into MongoDB
mgdb.tasks.insert_one(mg_data)
logger.info(result_message)
osd_weight_step = ceph.osd_weight_step
cluster_status = ceph.get_cluster_status()
osd_data = ceph.get_osd_status_datas()
osds_hight_target = calculate_target_crush_weight(osd_data)
data = ceph.get_cluster_detail()
if not data:
result_message = 'Get cluster info is failed. OSD weight down adjustment aborted.'
log_and_insert_result(result_message, 0)
return result_message
# Check for blocked requests in the cluster
summary = data["health"]["summary"] if "health" in data and "summary" in data["health"] else None
try:
summary = data["health"]["summary"] if "health" in data and "summary" in data["health"] else None
if summary and len(summary) > 0:
for item in summary:
if "noout" in item.get("summary", ""):
logger.info('cluster set noout 1')
result_message = 'Cluster status is noout. OSD weight down adjustment aborted.'
log_and_insert_result(result_message, 0)
break
else:
result_message = process_cluster_info(osds_hight_target, cluster_status, osd_weight_step)
else:
logger.info('start exec...')
result_message = process_cluster_info(osds_hight_target, cluster_status, osd_weight_step)
return result_message
except (subprocess.CalledProcessError, ValueError) as e:
result_message = f"Failed to get cluster status: {e}"
log_and_insert_result(result_message, 0)
return result_message
2.3.4.5 自动对于up状态的osd做拉升处理场景
- 逻辑设计:

- ceph crush weight up incress 场景自动处理
如上图自动化处理逻辑流程所示:
- ceph_manager组件根据设置的定时任务,会轮询触发celery task。
- 首先会判断集群是否处于noout状态,若处于noout状态(默认为人工介入维护状态),则本次worker任务结束。
- 若未处于noout状态,则进入筛选器开始筛选:
- 筛选状态为UP的osd;
- 并且osd的利用率小于80%的;(可以配置该参数)
- osd的reweight不等于0;
- 磁盘大小符合配置要求,(可以根据需求选择调整多大容量的盘)并且不在stop_pools中的(因其他原因如阀值,停止的osd插入到mongodb中的)
- osd的crush weight不等于目标值(通过磁盘大小自动计算)
- osd的crush weight大于0.2(防止操作新扩容节点)
- 若筛选器筛选的符合要求的osd为空,则本次worker任务结束。
- 若筛选器筛选的符合要求的osd为非空,则筛选优先级最高的1个osd进行调整(优先级:根据磁盘利用率判断,利用率越低优先级越高):
- 调整之前检测集群是否error,如果error则本次worker任务结束;
- 若集群未处于error状态,则进行crush weight调整操作,默认每次0.05(可配置),本次worker任务结束。
task代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
# auto: mmwei3
# date: 2023/08/26
import subprocess
from utils.ceph_util import CephUtils
from logger import get_logger
from scheduler import app
import os
import yaml
from datetime import datetime
from pymongo import MongoClient
from celery import current_task
from celery.result import AsyncResult
logger = get_logger()
ceph = CephUtils(config_file='/home/ceph_manager/middleware/config/ceph.yaml')
# Use context manager for file handling
config_file_path = os.path.abspath(os.path.join(os.path.dirname(__file__), "../config/common.yaml"))
with open(config_file_path) as f:
config = yaml.safe_load(f)
uri = config["mongodb"]["mongodb_uri"]
@app.task
def auto_adjust_osd_weight():
"""
This task adjusts OSD weights based on disk size and utilization.
:return: None
"""
# Access cluster_config and cluster_keyring using the ceph object
disk_size_threshold = ceph.disk_size_threshold
osd_weight_step = ceph.osd_weight_step
cluster_status = ceph.get_cluster_status()
osd_data = ceph.get_osd_status_datas()
cluster_name, cluster_cname = ceph.cluster_name, ceph.cluster_cname
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
def calculate_target_crush_weight(osd):
"""
Find eligible OSDs that are below the target.
:param osd: OSD data
:return: Eligible OSD or None
"""
GB_TO_BYTES = 1024 * 1024 * 1024
if osd["type"] == "osd" and osd['status'] == 'up' and osd['utilization'] < 80:
osd_size_gb = osd["kb"] / GB_TO_BYTES
if osd_size_gb > disk_size_threshold and 0.1 < osd["crush_weight"] <= osd_size_gb - 0.001:
osd['target_weight'] = osd_size_gb
return osd
return None
try:
osds_below_target = min(filter(None, (calculate_target_crush_weight(osd) for osd in osd_data)),
key=lambda x: x["utilization"], default=None)
logger.info('osds_below_target:')
logger.info(osds_below_target)
if osds_below_target and 'HEALTH_ERROR' not in cluster_status:
next_crush_weight = min(osds_below_target['crush_weight'] + osd_weight_step, osds_below_target['target_weight'])
logger.info('Starting OSD weight UP adjustment...')
logger.info('next_crush_weight:')
logger.info(next_crush_weight)
set_osd_crush_weight = ceph.set_osd_crush_weight(osds_below_target['id'], next_crush_weight)
effect = 1 if set_osd_crush_weight else 0
result_message = (f"Adjusting OSD weight up for osd_name: {osds_below_target['name']} "
f"to crush_weight: {next_crush_weight}, OSD weight adjustment {'completed.' if set_osd_crush_weight else 'exec failed.'}")
else:
effect = 0
result_message = 'Cluster status is not OK. OSD weight up adjustment aborted.' if 'HEALTH_ERROR' in cluster_status \
else 'There are no up status osd weight needs to be increased. OSD weight up adjustment aborted.'
except (subprocess.CalledProcessError, ValueError) as e:
effect = 0
result_message = f'Failed to get cluster status: {e}'
mgdb = MongoClient(uri).ceph
task_id = current_task.request.id
result_obj = AsyncResult(task_id)
task_status = result_obj.status
logger.info(f"Task ID {task_id} status: {task_status}")
# task_status_flag is 0: wait update task status filed; 1 already update task status filed
mg_data = {'status': 1, 'create_time': current_time, 'name': 'auto_adjust_osd_weight', 'result': result_message,
'task_id': task_id, 'is_effect': effect, 'task_status': task_status, 'cluster_name': cluster_name,
'cluster_cname': cluster_cname, 'task_type': '自动处理', 'uname': '对于up状态的osd做拉升处理场景'}
# Insert data into MongoDB
mgdb.tasks.insert_one(mg_data)
logger.info(result_message)
return result_message
2.3.4.6 自动处理单个osd上承载的pg不均衡问题或者数据再均衡

逻辑设计:

(新方案)

…
…
…
3、部署安装
3.1 公共组件部署
- MongoDB:
[root@dlp ~]# docker run --name mongo -v /data/mongodb:/data/db --restart always -p 27017:27017 -d com/stc-docker-private/mmwei3/mongodb:3.6.8 mongod --auth
# 初始化
db.createUser(
{
user:'root',
pwd:'c2dadawdPfHTOEjZd'
roles:[{role:'root',db:'admin'}]
}
);
docker exec -it mongo mongo admin
db.createUser({user:'root',pwd:'dadaPfHTOEjZd', roles:[{role:'root',db:'admin'}]});
db.auth('root','cwdafHTOEjZd')
- Redis
[root@dlp ~]# docker run --restart=always --log-opt max-size=100m --log-opt max-file=2 -p 6379:6379 --name redis -v /data/redis/redis.conf:/etc/redis/redis.conf -v /data/redis/data:/data -d stc-docker-private/mmwei3/redis:6.2.4 --appendonly yes --requirepass c2xxxxxd
- Ceph_auto
[root@dlp ~]# docker run -d --tty=true --net=host --restart=always --privileged --name=ceph-auto -v /etc/localtime:/etc/localtime:ro -v /etc/ceph:/etc/ceph:ro -v /home/ceph_auto:/home/ceph_auto:rw ceph-auto:v1.2.0
# docker run -d --net=host --tty=true --restart=always --privileged --name=ceph_manager -v /etc/localtime:/etc/localtime:ro -v /etc/ceph:/etc/ceph:ro --privileged artifacts.iflytek.com/stc-docker-private/mmwei3/ceph_manager:v1.1 /usr/sbin/init
0 1 * * * echo > /var/log/ceph_manager/ceph_celery_worker.log
3.2 配置修改
- 修改配置文件/home/ceph_auto/middleware/config/common.yaml
redis:
redis_uri: redis://:password@x.x.x.x:6379/0
mongodb:
mongodb_uri: mongodb://root:password@x.x.x.x:27017/admin
- 修改ceph相关配置/home/ceph_auto/middleware/config/ceph.yaml
# ceph.yaml
# Ceph 集群相关配置参数
cluster:
cluster_name: rg1-test # Ceph 集群名称
cluster_cname: 测试集群 # Ceph 集群名称
monitor_host: 172.30.1.1 # Ceph Monitor 的 IP 地址
monitor_port: 6789 # Ceph Monitor 的端口号
admin_user: admin # Ceph 集群管理员用户名
cluster_conf: /etc/ceph/ceph.conf # Ceph conf
admin_keyring: /etc/ceph/ceph.client.admin.keyring # Ceph 集群管理员 keyring 文件的路径
ceph_version: 10
crush_type: rack
disk_size_threshold: 2 # 用于筛选出满足特定大小要求的 OSD。只有当OSD的大小(以TB 为单位)大于 size_threshold 时,才会进行自动调整范围
pool:
# pool_name: sata_pool # 存储 pool 的名称
pool_size: 3 # 存储 pool 的副本数
pool_pg_num: 64 # 存储 pool 的 Placement Group 数量
osd_weight_step: 0.05 # OSD 权重调整的步长
down_osd_threshold: 20 # 处于 down 状态的 OSD 数量阈值,超过该阈值停止自动stop 高的OSD
osd_height_capacity_threshold: 0.20 # 最高的OSD阈值,超过该阈值则会自动stop 高的OSD
request_block_threshold: 100 # OSD 请求阻塞的阈值,超过该阈值自动进行 OSD 处理恢复
- 修改monitor相关配置/home/ceph_auto/middleware/config/monitor.yaml
monitor:
monitor_interval: 60
monitor_threshold: 90
sms:
iphone: ['17855350258']
mail:
mail_to: ['mmwei3@xxx.com']
- 调度相关日志/home/ceph_auto/middleware/config/scheduler.yaml
(已经采用数据库方式,改配置忽略)
# scheduler.yaml 忽略 已经采用数据库方式,改配置忽略
redis:
broker_url: redis://:thinkbig1@127.0.0.1:6379/0
result_backend: redis://:thinkbig1@127.0.0.1:6379/0
beat_schedule:
cluster_capacity_auto: # 容量超阀值自动处理
task: tasks.cluster_capacity_auto.cluster_capacity_auto
schedule: 120 # 每120秒执行一次
auto_adjust_osd_weight: # 对于up状态的osd做拉升处理,step: 0.05
task: tasks.auto_adjust_osd_weight.auto_adjust_osd_weight
schedule: 240 # 每240秒执行一次
auto_adjust_osd_weight_down: # 对于down状态的osd做降权处理,step: 0.05
task: tasks.auto_adjust_osd_weight_down.auto_adjust_osd_weight_down
schedule: 150 # 每150秒执行一次
# get_cluster_status:
# task: tasks.get_cluster_status.get_cluster_status
# schedule: 100 # 每100秒执行一次
# send_mails:
# tasks: tasks.send_mails.send_mails
# schedule: 100 # 每80秒执行一次
pr_str1:
task: tasks.pr_str1.pr_str1
schedule: 100 # 每100秒执行一次
collect_osd_datas: # 采集osd的详细信息入库,用于数据分析
task: tasks.collect_osd_datas.collect_osd_datas
schedule: 3600 # 每3600秒(1小时)执行一次
collect_osd_status: # 采集osd的状态概览入库,用于数据分析
task: tasks.collect_osd_status.collect_osd_status
schedule: 7200 # 每7200秒(2小时)执行一次
# down_disk_auto:
# tasks: tasks.down_disk_auto
# schedule: 100 # 每30秒执行一次
# handle_request_block:
# tasks: tasks.handle_request_block
# schedule: 300 # 每15秒执行一次
3.3 访问方式
1、执/home/ceph_auto/middleware/start_celery.sh
#!/bin/bash
pkill -f "celery worker" -9
pkill -f "celery beat" -9
pkill -f "celery cephAuto" -9
pkill -f "flower" -9
celery -A scheduler beat -l info -f /var/log/ceph_auto/ceph_celery_scheduler.log &
celery -A worker worker -l DEBUG -f /var/log/ceph_auto/ceph_celery_worker.log &
celery --broker=redis://:thinkbig1@127.0.0.1:6379/0 flower --address=0.0.0.0 --port=5555 &
python3 cephAuto.py &
# 前端:
# cd /home/ceph_auto/fronted_vue/ && pnpm run build
# 打开浏览器访问x.x.x.x即可
3.4 问题
yum install xdg-utils zlib-devel autoconf automake libtool nasm npm -y
--privileged 和 /usr/sbin/init
pnpm cache clear --force
pnpm install
4、页面预览
4.1 登陆首页

4.2 任务分析页面


4.3 OSD管理页面
- (操作权限已经限制)

4.4 任务配置管理页面

4.5 任务文档页面
- 提供本平台各个任务逻辑及使用说明




5. 自动化的优势和挑战
5.1 优势
在开发部署Ceph分布式存储自动化运维平台后,相对运维获得了许多显著的优势:
- 效率提升: 自动化任务的引入显著提高了Ceph集群的管理效率。例如,自动调整OSD权重和负载均衡可以在不影响业务的情况下优化集群性能,而无需手动干预。
- 负担减轻: 管理庞大和复杂的Ceph集群通常是一项耗时而繁琐的任务。自动化使ceph运维管理员从重复性、机械性的任务中解放出来,能够更专注于战略性的工作,提高整体的工作满足感。
- 实时性提升: 在高负载环境中,实时性是关键。自动化运维平台能够及时响应集群状态的变化,执行相应的调整和优化,确保集群在不同负载下都能保持稳定。
5.2 挑战
尽管该平台集成了自动化带来了许多优势,但也面临一些挑战:
- 复杂性: Ceph集群的复杂性和规模可能导致自动化方案的设计和实施变得复杂。解决方案是采用模块化设计,将自动化任务分解成小的、可管理的部分,并确保模块之间的协同工作。
- 实时性要求: 有些自动化任务需要在集群状态发生变化时立即生效。解决方案包括采用实时监控和响应机制,确保自动化任务能够及时感知变化并作出相应调整。
- 安全性考虑: 自动化平台涉及对关键基础设施的自动控制,因此必须对安全性进行充分考虑。解决方案包括采用安全的认证授权机制、加密通信等手段,确保自动化过程的安全性。
6. 未来发展和扩展
6.1 计划的新功能
未来版本功能计划:集成预测和智能优化
在未来的版本中,我计划引入一项重要的新功能,即集成预测和智能优化。这一功能旨在提高Ceph分布式存储自动化运维平台的智能化水平,使其更好地适应不断变化的环境和负载。
-
预测模型引入: 我将引入先进的预测模型,通过对历史数据的深入分析,构建能够准确预测未来集群状态的模型。这将涵盖各种关键指标,如负载趋势、磁盘利用率、网络性能、磁盘寿命等。
-
智能优化: 基于预测模型的输出,我将实现智能优化策略。这包括对OSD权重的自动调整、PG分布的智能平衡、以及针对不同工作负载的动态调整。通过智能优化,平台将更灵活地适应不同的工作负载需求,提高整体性能。
-
自动应对变化和波动: 集成的预测和智能优化模块将实时监测集群状态,当检测到变化和波动时,自动触发相应的调整策略(即:celery任务动态化,自适应化)。这将大大提高系统的实时性和适应性,确保在各种情况下都能保持高效稳定。
-
用户友好性增强: 引入这一功能的同时,我也将注重用户友好性的提升。通过直观的可视化界面,ceph manager管理员可以清晰地了解到预测结果和优化效果,同时能够灵活地进行手动干预。
-
反馈机制: 我计划建立一个完善的反馈机制,从用户使用中收集数据和反馈,不断优化预测模型和智能优化策略,确保其能够适应不同环境和使用场景(比如块存储、对象存储、文件存储等)以及不同的规模。
通过引入这一功能,我期望Ceph分布式存储自动化运维平台能够更好地满足用户的需求,提供更智能、更高效的管理体验。
7. 代码示例
7.1 api

import axios from 'axios';
export interface ProfileBasicRes {
status: number;
video: {
mode: string;
acquisition: {
resolution: string;
frameRate: number;
};
encoding: {
resolution: string;
rate: {
min: number;
max: number;
default: number;
};
frameRate: number;
profile: string;
};
};
audio: {
mode: string;
acquisition: {
channels: number;
};
encoding: {
channels: number;
rate: number;
profile: string;
};
};
}
export function queryProfileBasic() {
return axios.get<ProfileBasicRes>('/api/profile/basic');
}
export type operationLogRes = Array<{
key: string;
contentNumber: string;
updateContent: string;
status: number;
updateTime: string;
}>;
export function queryOperationLog() {
return axios.get<operationLogRes>('/api/operation/log');
}
7.2 router

import { DEFAULT_LAYOUT } from '../base';
import { AppRouteRecordRaw } from '../types';
const PROFILE: AppRouteRecordRaw = {
path: '/profile',
name: 'profile',
component: DEFAULT_LAYOUT,
meta: {
locale: 'menu.profile',
requiresAuth: true,
icon: 'icon-file',
order: 4,
},
children: [
{
path: 'basic',
name: 'Basic',
component: () => import('@/views/profile/basic/index.vue'),
meta: {
locale: 'menu.profile.basic',
requiresAuth: true,
roles: ['admin'],
hideInMenu: true,
},
},
],
};
export default PROFILE;
7.3 index.vue

<template>
<div class="container">
<Breadcrumb :items="['menu.storage', 'menu.storage.storageOSD']" />
<a-card class="general-card" :title="$t('menu.storage.storageOSD')">
<a-row>
<a-col :flex="1">
<a-form
:model="formModel"
:label-col-props="{ span: 4 }"
:wrapper-col-props="{ span: 18 }"
label-align="left"
>
<a-row :gutter="16">
<a-col :span="12">
<a-form-item field="name" :label="$t('storageOSD.form.name')">
<a-input
v-model="formModel.name"
:placeholder="$t('storageOSD.form.name.placeholder')"
/>
</a-form-item>
</a-col>
<a-col :span="12">
<a-form-item
field="hostname"
:label="$t('storageOSD.form.hostname')"
>
<a-input
v-model="formModel.hostname"
:placeholder="$t('storageOSD.form.hostname.placeholder')"
/>
</a-form-item>
</a-col>
<a-col :span="12">
<a-form-item
field="crush_name"
:label="$t('storageOSD.form.crush_name')"
>
<a-select
v-model="formModel.crush_name"
:options="contentTypeOptions"
:placeholder="$t('storageOSD.form.selectDefault')"
allow-clear
/>
</a-form-item>
</a-col>
<a-col :span="12">
<a-form-item
field="status"
:label="$t('storageOSD.form.status')"
>
<a-select
v-model="formModel.status"
:options="statusOptions"
:placeholder="$t('storageOSD.form.selectDefault')"
allow-clear
/>
</a-form-item>
</a-col>
</a-row>
</a-form>
</a-col>
<a-divider style="height: 84px" direction="vertical" />
<a-col :flex="'86px'" style="text-align: right">
<a-space direction="vertical" :size="18">
<a-button type="primary" @click="search">
<template #icon>
<icon-search />
</template>
{{ $t('storageOSD.form.search') }}
</a-button>
<a-button @click="reset">
<template #icon>
<icon-refresh />
</template>
{{ $t('storageOSD.form.reset') }}
</a-button>
</a-space>
</a-col>
</a-row>
<a-divider style="margin-top: 0" />
<a-row style="margin-bottom: 16px">
<a-col :span="12">
<a-space>
<a-button type="primary" disabled>
<template #icon>
<icon-plus />
</template>
{{ $t('storageOSD.operation.create') }}
</a-button>
<a-upload action="/">
<template #upload-button>
<a-button disabled>
{{ $t('storageOSD.operation.import') }}
</a-button>
</template>
</a-upload>
</a-space>
</a-col>
<a-col
:span="12"
style="display: flex; align-items: center; justify-content: end"
>
<a-button>
<template #icon>
<icon-download />
</template>
{{ $t('storageOSD.operation.download') }}
</a-button>
<a-tooltip :content="$t('storageOSD.actions.refresh')">
<div class="action-icon" @click="search"
><icon-refresh size="18"
/></div>
</a-tooltip>
<a-dropdown @select="handleSelectDensity">
<a-tooltip :content="$t('storageOSD.actions.density')">
<div class="action-icon"><icon-line-height size="18" /></div>
</a-tooltip>
<template #content>
<a-doption
v-for="item in densityList"
:key="item.value"
:value="item.value"
:class="{ active: item.value === size }"
>
<span>{{ item.name }}</span>
</a-doption>
</template>
</a-dropdown>
<a-tooltip :content="$t('storageOSD.actions.columnSetting')">
<a-popover
trigger="click"
position="bl"
@popup-visible-change="popupVisibleChange"
>
<div class="action-icon"><icon-settings size="18" /></div>
<template #content>
<div id="tableSetting">
<div
v-for="(item, index) in showColumns"
:key="item.dataIndex"
class="setting"
>
<div style="margin-right: 4px; cursor: move">
<icon-drag-arrow />
</div>
<div>
<a-checkbox
v-model="item.checked"
@change="
handleChange($event, item as TableColumnData, index)
"
>
</a-checkbox>
</div>
<div class="title">
{{ item.title === '#' ? '序列号' : item.title }}
</div>
</div>
</div>
</template>
</a-popover>
</a-tooltip>
</a-col>
</a-row>
<a-table
row-key="name"
:loading="loading"
:pagination="pagination"
:columns="(cloneColumns as TableColumnData[])"
:data="renderData"
:bordered="false"
:stripe="true"
:size="size"
@page-change="onPageChange"
>
<template
#name-filter="{
filterValue,
setFilterValue,
handleFilterConfirm,
handleFilterReset,
}"
>
<div class="custom-filter">
<a-space direction="vertical">
<a-input
:model-value="filterValue[0]"
@input="(value) => setFilterValue([value])"
/>
<div class="custom-filter-footer">
<a-button @click="handleFilterConfirm">Confirm</a-button>
<a-button @click="handleFilterReset">Reset</a-button>
</div>
</a-space>
</div>
</template>
<template #index="{ rowIndex }">
{{ rowIndex + 1 + (pagination.current - 1) * pagination.pageSize }}
</template>
<template #contentType="{ record }">
<a-space>
<a-avatar
v-if="record.contentType === 'img'"
:size="16"
shape="square"
>
<img
alt="avatar"
src="//p3-armor.byteimg.com/tos-cn-i-49unhts6dw/581b17753093199839f2e327e726b157.svg~tplv-49unhts6dw-image.image"
/>
</a-avatar>
<a-avatar
v-else-if="record.contentType === 'horizontalVideo'"
:size="16"
shape="square"
>
<img
alt="avatar"
src="//p3-armor.byteimg.com/tos-cn-i-49unhts6dw/77721e365eb2ab786c889682cbc721c1.svg~tplv-49unhts6dw-image.image"
/>
</a-avatar>
<a-avatar v-else :size="16" shape="square">
<img
alt="avatar"
src="//p3-armor.byteimg.com/tos-cn-i-49unhts6dw/ea8b09190046da0ea7e070d83c5d1731.svg~tplv-49unhts6dw-image.image"
/>
</a-avatar>
{{ $t(`storageOSD.form.contentType.${record.contentType}`) }}
</a-space>
</template>
<template #filterType="{ record }">
{{ $t(`storageOSD.form.filterType.${record.filterType}`) }}
</template>
<template #status="{ record }">
<span v-if="record.status === 'down'" class="circle error"></span>
<span v-else class="circle pass"></span>
{{ $t(`storageOSD.form.status.${record.status}`) }}
</template>
<!-- <template #operations>-->
<!-- <a-button v-permission="['admin']" type="text" size="small">-->
<!-- {{ $t('storageOSD.columns.operations.view') }}-->
<!-- </a-button>-->
<!-- </template>-->
</a-table>
</a-card>
</div>
</template>
<script lang="ts" setup>
import { computed, ref, reactive, watch, nextTick, h } from 'vue';
import { useI18n } from 'vue-i18n';
import useLoading from '@/hooks/loading';
import {
getStorageOSDList,
PolicyRecord,
PolicyParams,
getStorageCrush,
} from '@/api/storage';
import { Pagination } from '@/types/global';
import type { SelectOptionData } from '@arco-design/web-vue/es/select/interface';
import type { TableColumnData } from '@arco-design/web-vue/es/table/interface';
import cloneDeep from 'lodash/cloneDeep';
import Sortable from 'sortablejs';
import { IconSearch } from '@arco-design/web-vue/es/icon';
type SizeProps = 'mini' | 'small' | 'medium' | 'large';
type Column = TableColumnData & { checked?: true };
const generateFormModel = () => {
return {
name: '',
hostname: '',
crush_name: '',
pgs: '',
reweight: '',
cluster_name: '',
cluster_cname: '',
status: '',
crush_weight: '',
kb: '',
kb_avail: '',
kb_used: '',
utilization: '',
var: '',
at_time: '',
};
};
const { loading, setLoading } = useLoading(true);
const { t } = useI18n();
const renderData = ref<PolicyRecord[]>([]);
const formModel = ref(generateFormModel());
const cloneColumns = ref<Column[]>([]);
const showColumns = ref<Column[]>([]);
const size = ref<SizeProps>('medium');
const basePagination: Pagination = {
current: 1,
pageSize: 20,
};
const pagination = reactive({
...basePagination,
});
const densityList = computed(() => [
{
name: t('storageOSD.size.mini'),
value: 'mini',
},
{
name: t('storageOSD.size.small'),
value: 'small',
},
{
name: t('storageOSD.size.medium'),
value: 'medium',
},
{
name: t('storageOSD.size.large'),
value: 'large',
},
]);
const columns = computed<TableColumnData[]>(() => [
{
title: t('storageOSD.columns.index'),
dataIndex: 'index',
slotName: 'index',
},
{
title: t('storageOSD.columns.cluster_cname'),
dataIndex: 'cluster_cname',
},
{
title: t('storageOSD.columns.cluster_name'),
dataIndex: 'cluster_name',
sortable: {
sortDirections: ['ascend', 'descend'],
},
},
{
title: t('storageOSD.columns.crush_name'),
dataIndex: 'crush_name',
filterable: {
filter: (value, record) => record.crush_name.includes(value),
slotName: 'name-filter',
icon: () => h(IconSearch),
},
},
{
title: t('storageOSD.columns.hostname'),
dataIndex: 'hostname',
filterable: {
filter: (value, record) => record.hostname.includes(value),
slotName: 'name-filter',
icon: () => h(IconSearch),
},
},
{
title: t('storageOSD.columns.name'),
dataIndex: 'name',
slotName: 'name',
filterable: {
filter: (value, record) => record.name.includes(value),
slotName: 'name-filter',
icon: () => h(IconSearch),
},
},
{
title: t('storageOSD.columns.kb'),
dataIndex: 'kb',
sortable: {
sortDirections: ['ascend', 'descend'],
},
filterable: {
filters: [
{
text: '> 1000',
value: '1000',
},
{
text: '> 5000',
value: '5000',
},
],
filter: (value, record) => record.kb > value,
multiple: true,
},
},
{
title: t('storageOSD.columns.kb_avail'),
dataIndex: 'kb_avail',
sortable: {
sortDirections: ['ascend', 'descend'],
},
},
{
title: t('storageOSD.columns.kb_used'),
dataIndex: 'kb_used',
sortable: {
sortDirections: ['ascend', 'descend'],
},
},
{
title: t('storageOSD.columns.utilization'),
dataIndex: 'utilization',
sortable: {
sortDirections: ['ascend', 'descend'],
},
filterable: {
filters: [
{
text: '> 90%',
value: '90',
},
{
text: '> 80%',
value: '80',
},
],
filter: (value, record) => record.utilization > value,
multiple: true,
},
},
{
title: t('storageOSD.columns.reweight'),
dataIndex: 'reweight',
slotName: 'reweight',
sortable: {
sortDirections: ['ascend', 'descend'],
},
filterable: {
filters: [
{
text: '> 0.5',
value: '0.5',
},
{
text: '> 1.0',
value: '1.0',
},
],
filter: (value, record) => record.reweight > value,
multiple: true,
},
},
{
title: t('storageOSD.columns.crush_weight'),
dataIndex: 'crush_weight',
slotName: 'crush_weight',
sortable: {
sortDirections: ['ascend', 'descend'],
},
filterable: {
filters: [
{
text: '> 5.0',
value: '5.0',
},
{
text: '> 7.0',
value: '7.0',
},
],
filter: (value, record) => record.crush_weight > value,
multiple: true,
},
},
{
title: t('storageOSD.columns.pgs'),
dataIndex: 'pgs',
slotName: 'pgs',
sortable: {
sortDirections: ['ascend', 'descend'],
},
},
{
title: t('storageOSD.columns.status'),
dataIndex: 'status',
slotName: 'status',
filterable: {
filters: [
{
text: 'up',
value: 'up',
},
{
text: 'down',
value: 'down',
},
],
filter: (value, row) => row.status.includes(value),
},
},
{
title: t('storageOSD.columns.at_time'),
dataIndex: 'at_time',
slotName: 'at_time',
},
// {
// title: t('storageOSD.columns.operations'),
// dataIndex: 'operations',
// slotName: 'operations',
// },
]);
const statusOptions = computed<SelectOptionData[]>(() => [
{
label: t('storageOSD.form.status.up'),
value: 'up',
},
{
label: t('storageOSD.form.status.down'),
value: 'down',
},
]);
const fetchData = async (
params: PolicyParams = { current: 1, pageSize: 20 }
) => {
setLoading(true);
try {
const { data } = await getStorageOSDList(params);
renderData.value = data.list;
pagination.current = params.current;
pagination.total = data.total;
} catch (err) {
// you can report use errorHandler or other
} finally {
setLoading(false);
}
};
const search = () => {
fetchData({
...basePagination,
...formModel.value,
} as unknown as PolicyParams);
};
const onPageChange = (current: number) => {
fetchData({ ...basePagination, current });
};
fetchData();
const reset = () => {
formModel.value = generateFormModel();
};
const crushDatas = ref([]);
const getCrushData = async () => {
try {
// Assuming getStorageCrush returns a Promise
const data = await getStorageCrush();
// Process the data and set crushDatas
crushDatas.value = data.data.list;
return crushDatas.value;
} catch (error) {
return [];
}
};
getCrushData();
const contentTypeOptions = computed<SelectOptionData[]>(() => {
// Check if crushDatas.value is an array before using map
return crushDatas.value.map((item) => ({
label: item,
value: item,
}));
});
const handleChange = (checked: any, column: any, index: any) => {
const newColumns = [...cloneColumns.value];
if (!checked) {
const columnIndex = newColumns.findIndex(
(item) => item.dataIndex === column.dataIndex
);
if (columnIndex !== -1) {
newColumns.splice(columnIndex, 1);
}
} else {
newColumns.splice(index, 0, column);
}
// 更新 cloneColumns
cloneColumns.value = newColumns;
};
const handleSelectDensity = (
val: string | number | Record<string, any> | undefined,
e: Event
) => {
size.value = val as SizeProps;
};
// const handleChange = (
// checked: boolean | (string | boolean | number)[],
// column: Column,
// index: number
// ) => {
// if (!checked) {
// cloneColumns.value = showColumns.value.filter(
// (item) => item.dataIndex !== column.dataIndex
// );
// } else {
// cloneColumns.value.splice(index, 0, column);
// }
// };
const exchangeArray = <T extends Array<any>>(
array: T,
beforeIdx: number,
newIdx: number,
isDeep = false
): T => {
const newArray = isDeep ? cloneDeep(array) : array;
if (beforeIdx > -1 && newIdx > -1) {
// 先替换后面的,然后拿到替换的结果替换前面的
newArray.splice(
beforeIdx,
1,
newArray.splice(newIdx, 1, newArray[beforeIdx]).pop()
);
}
return newArray;
};
const popupVisibleChange = (val: boolean) => {
if (val) {
nextTick(() => {
const el = document.getElementById('tableSetting') as HTMLElement;
const sortable = new Sortable(el, {
onEnd(e: any) {
const { oldIndex, newIndex } = e;
exchangeArray(cloneColumns.value, oldIndex, newIndex);
exchangeArray(showColumns.value, oldIndex, newIndex);
},
});
});
}
};
watch(
() => columns.value,
(val) => {
cloneColumns.value = cloneDeep(val);
cloneColumns.value.forEach((item, index) => {
item.checked = true;
});
showColumns.value = cloneDeep(cloneColumns.value);
},
{ deep: true, immediate: true }
);
</script>
<script lang="ts">
export default {
name: 'StorageOSD',
};
</script>
<style scoped lang="less">
.container {
padding: 0 20px 20px 20px;
}
:deep(.arco-table-th) {
&:last-child {
.arco-table-th-item-title {
margin-left: 16px;
}
}
}
.action-icon {
margin-left: 12px;
cursor: pointer;
}
.active {
color: #0960bd;
background-color: #e3f4fc;
}
.setting {
display: flex;
align-items: center;
width: 200px;
.title {
margin-left: 12px;
cursor: pointer;
}
}
</style>
8. 共同讨论
8.1 缺陷沟通
- 沟通交流: 如果需要源代码,请留言邮箱📮 方便联系。
- 平台源码: 新版本后续会脱敏后发布到github

鸿蒙生态一站式服务平台。
更多推荐

 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)